 Sergey Diakov
Sergey Diakov

⬤ Fresh rating data circulating in AI research circles shows a massive performance jump between Anthropic's newest Claude 4.5 Opus Thinking and earlier versions. According to estimates shared by @scaling01 using Glicko-2 or Elo-style calculations, the latest model would theoretically win more than 99% of head-to-head matchups against Claude 3 Opus. The data's also tied to something called the "Lisan Index"—basically an attempt to create one unified ranking system for AI models.
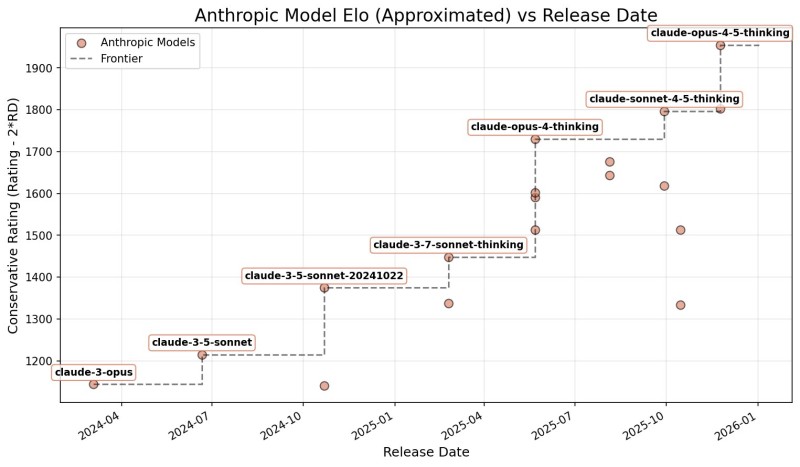
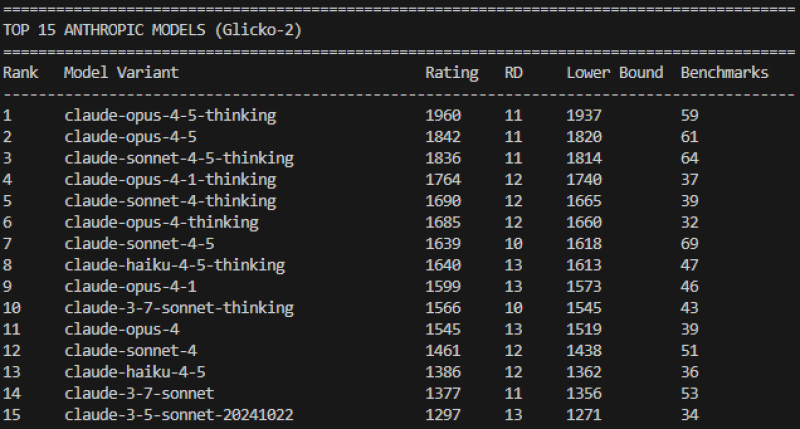
⬤ Tables accompanying the post place Claude Opus 4.5 Thinking at the top with a 1960 rating, followed by Claude Opus 4.5 at 1842 and Claude Sonnet 4.5 Thinking at 1836. Older releases like Claude 3.5 Sonnet, Claude 3 Opus, and the October 2024 Sonnet variant sit noticeably lower. A separate chart tracking these conservative scores over time shows steady upward momentum as new Claude versions rolled out through 2024, 2025, and into early 2026.
⬤ The post suggests we're watching a "benchmark monopoly" slowly form—standardized evaluation systems gaining traction across the industry. It touches on how competing models stack up in this landscape while highlighting the clear capability leap from Claude 3-series to 4.5-series, especially the "Thinking" variants built for handling tougher reasoning tasks.

⬤ What makes this interesting? It's hard evidence of how fast Claude's gotten better across successive releases. With newer models posting dramatically higher ratings, these benchmarks aren't just numbers—they're shaping the whole conversation around AI competitiveness, technical maturity, and whether the industry needs unified evaluation standards.
 Sergey Diakov
Sergey Diakov


