 Saad Ullah
Saad Ullah

⬤ Anthropic just dropped Claude Opus 4.5, their newest flagship model, and the numbers look solid. The company says it's crushing previous versions in coding, tool use, and reasoning while costing about one-third per token compared to what came before. That's a pretty significant jump in both performance and affordability for a high-end AI model.
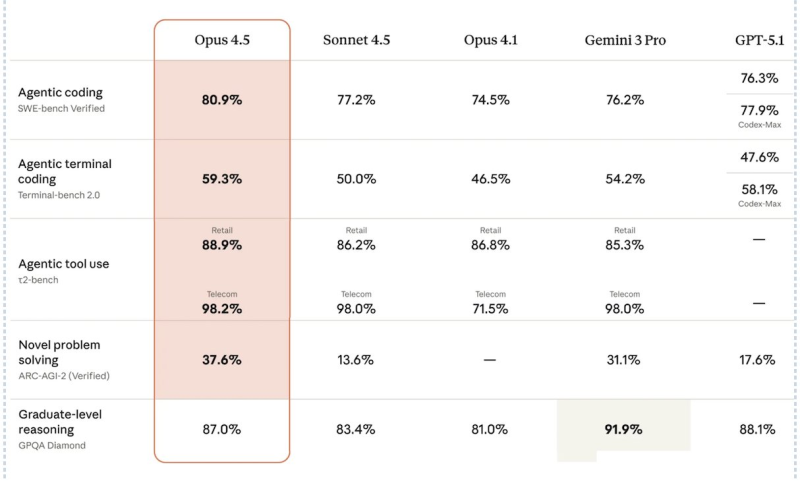
⬤ The benchmark results tell an interesting story. On SWE-bench Verified—which tests how well AI handles real coding tasks—Opus 4.5 scored 80.9%, beating out Sonnet 4.5 (77.2%), Opus 4.1 (74.5%), and Gemini 3 Pro (76.2%). When it comes to terminal coding via Terminal-bench 2.0, Opus 4.5 hit 59.3%, leaving Sonnet 4.5 at 50.0% and Opus 4.1 at 46.5% in the dust, while staying competitive with Gemini 3 Pro.
⬤ Tool use and reasoning metrics show similar strength. Opus 4.5 nailed 88.9% on retail scenarios and 98.2% on telecom scenarios in t2-bench testing. For novel problem solving (ARC-AGI-2 Verified), it reached 37.6%—ahead of both Sonnet 4.5 and Gemini 3 Pro. Graduate-level reasoning on GPQA Diamond came in at 87.0%, which trails Gemini 3 Pro's 91.9% but still holds its own against other top models.

⬤ Beyond raw performance, Anthropic added some practical features: adjustable "effort" settings for deeper thinking, auto-summarization for lengthy conversations, and better long-context handling. Combined with those lower token costs, Opus 4.5 reflects where the industry's heading—models that deliver strong results without breaking the bank, reshaping how companies think about deploying AI at scale.
 Saad Ullah
Saad Ullah


