 Alex Dudov
Alex Dudov

AI benchmarking just got more grounded. Zhipu AI has released ZClawBench, a framework that moves agent evaluation away from controlled lab conditions and into realistic, workflow-driven scenarios. Introduced via Hugging Face, the benchmark focuses on OpenClaw environments that reflect how AI actually gets used in production, setting a new reference point for applied agent testing.
116 Test Cases Spanning Automation, Coding, and Data Analysis
ZClawBench covers 116 diverse test cases built around three core domains: office automation, coding tasks, and data analysis operations. The benchmark evaluates several leading models including GLM-5-Turbo, GLM-5, Claude Opus 4.6, Gemini 3.1 Pro, MiniMax M2.5, and Kimi K2.5, measuring relative performance across information search, development operations, and multi-step task execution rather than isolated, single-turn metrics.
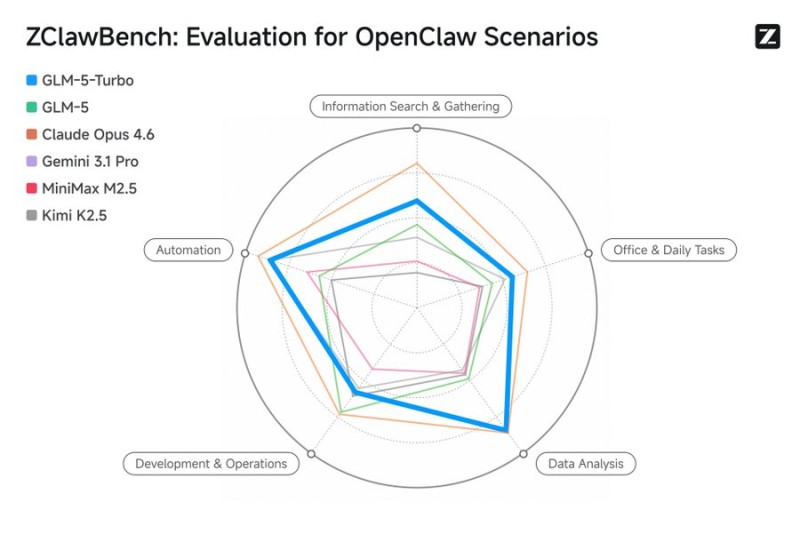
Why Practical Benchmarks Are Reshaping AI Evaluation
ZClawBench is part of a wider industry shift toward applied testing. Earlier this year, Alibaba Launches OmniWorldBench to Test 4D AI in Real-World Scenarios, targeting immersive and dynamic environments to assess how AI handles physical world complexity. On the developer tooling side, Cursor AI Launches Instant Grep With 13ms Search Speed, illustrating how performance under production conditions has become a central concern for AI toolmakers.
Together, these releases signal a clear direction: the industry is moving from theoretical metrics toward evaluation frameworks that mirror enterprise workflows and production pipelines. As AI agents become more embedded in automation and business operations, how they perform across practical, multi-step tasks matters more than ever. ZClawBench adds a concrete, reproducible way to measure that gap.
 Alex Dudov
Alex Dudov


