 Peter Smith
Peter Smith

⬤ OpenAI's newest GPT-5.2 model family is making waves in the benchmark world, especially when it comes to math. Recent publicly shared results show GPT-5.2 consistently ranking at the top of math-heavy evaluations, with FrontierMath being its strongest showing. The data reveals GPT-5.2 variants placed among the highest-performing models across both Tier 1–3 and Tier 4 categories.
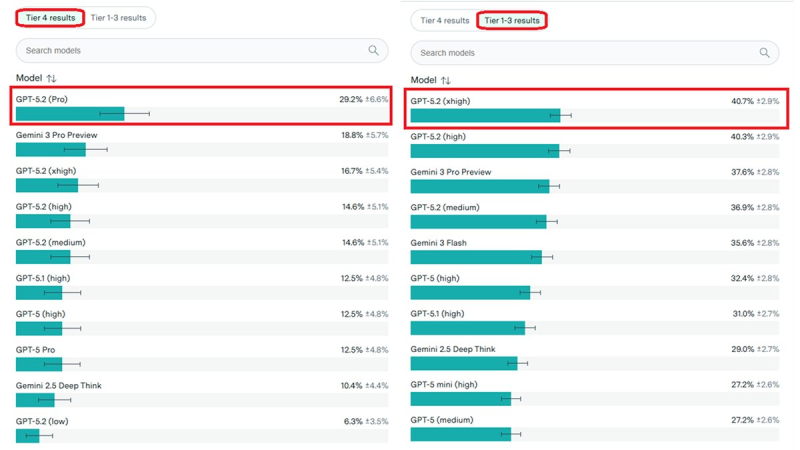
⬤ Here's what the numbers show: GPT-5.2 (xhigh) and GPT-5.2 (high) both scored above 40% in Tier 1–3 results, putting them in the top tier. Over in Tier 4 results, GPT-5.2 Pro came out on top, beating several competing models from other AI labs—including their preview and flash versions. These aren't your typical language tests either; they're specifically designed to push advanced mathematical reasoning to the limit.
⬤ GPT-5.2's also been tackling Erdős-style math problems, which are basically the gold standard for testing reasoning power. An internal OpenAI model apparently hit gold-level performance in last year's evaluations, so it's pretty clear the company's doubling down on math optimization with each new release.

⬤ Why does this matter? Mathematical reasoning benchmarks are becoming the go-to metric for figuring out which models can actually handle scientific research and technical work. Strong performance here could push adoption in advanced AI applications, though real-world use and competition will keep shifting as newer models and evaluation methods roll out.
 Peter Smith
Peter Smith


