 Saad Ullah
Saad Ullah

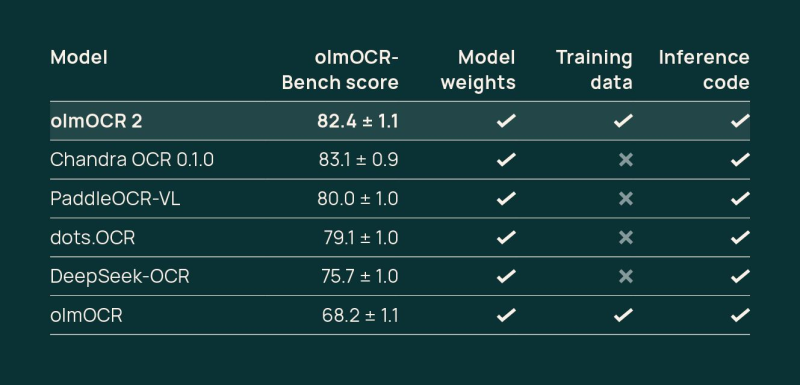
● In a recent tweet by Merve, the newly dropped OlmOCR 2 model is getting serious attention in the OCR world. The model crushed it with an 82.4 score on olmOCR-Bench—a solid jump from its previous 78.5. We're seeing improvements across every single document category, which is pretty impressive.
● What really stands out about OlmOCR 2 is how affordable it is. At just $178 per million pages, it's a steal for businesses and developers working with tons of documents. If you're processing massive amounts of data and don't want to empty your wallet, this model's basically a no-brainer.
● The whole thing runs under an Apache 2.0 license, so it's accessible for pretty much anyone who wants to integrate it into their systems. This open-source approach means OlmOCR 2 can spread quickly across the OCR market, especially for companies trying to automate document management or finally digitize those mountains of paper records.
● When it comes to the competition, OlmOCR 2 has definitely earned its spot at the top. With its speed, accuracy, and dirt-cheap pricing, it's leaving models like Chandra OCR, PaddleOCR-VL, and DeepSeek-OCR behind on the olmOCR-Bench leaderboard.
● If you need an OCR solution that actually works without destroying your budget, OlmOCR 2 is kind of a big deal. The performance boost across all categories plus the competitive pricing means it's going to stay relevant in the OCR space. For industries drowning in documents and data, this model's combination of high-speed processing and low costs makes it a seriously useful tool.
 Saad Ullah
Saad Ullah


