 Saad Ullah
Saad Ullah

⬤ Kimi-K2 Thinking has emerged as China's leading open-source AI model on the WeirdML benchmark, which tests real-world problem-solving through code reasoning, debugging, and iterative refinement. The benchmark puts models through five rounds of machine-learning tasks, measuring both reasoning accuracy and execution reliability.

⬤ With an average accuracy of 42.1%, Kimi-K2 ranks second among all open-source models—trailing only GPT-OSS-120B while surpassing Claude 4.1 Opus (Thinking) and Grok-4. This makes it the strongest Chinese open-source model tested to date. What's particularly impressive is that it achieved these results at an average run cost of just $0.08, making it one of the most cost-efficient models in its class—a crucial advantage for large-scale deployment.

⬤ The model shows strong performance on complex reasoning tasks, though it does exhibit some variability. While it handles sophisticated problems well, there are occasional inconsistencies in iterative runs, suggesting some instability under specific computational conditions.
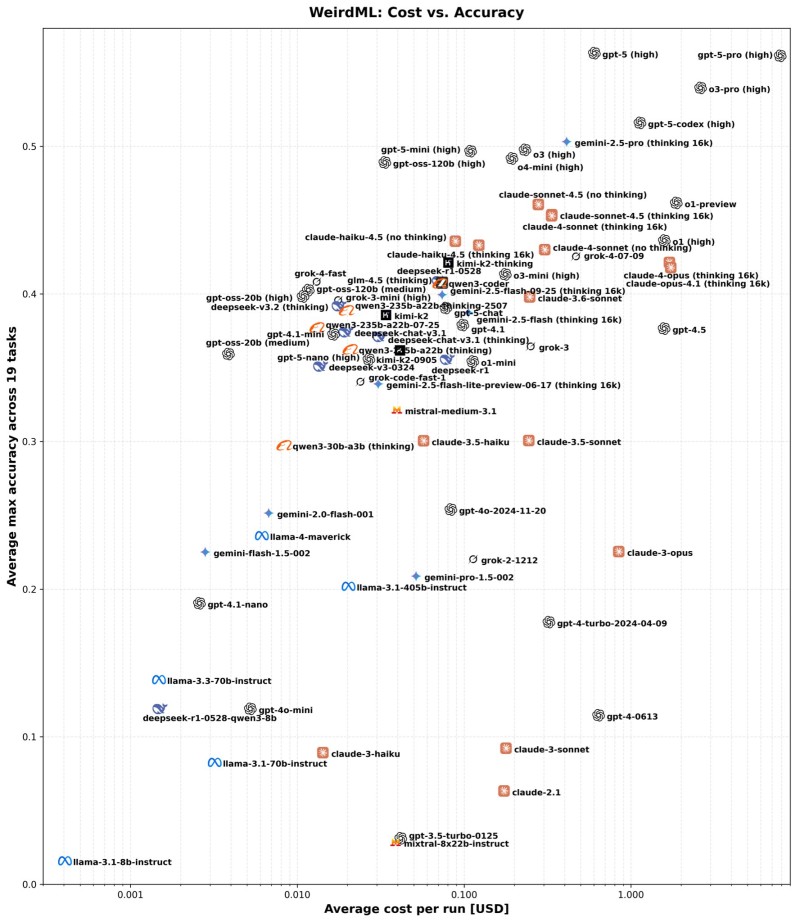
⬤ These results show that Chinese research labs are quickly narrowing the gap with leading proprietary systems like GPT-5 and Claude-Sonnet-4.5. Kimi-K2's combination of solid accuracy, low cost, and scalability makes it a compelling option for practical AI engineering applications.
 Saad Ullah
Saad Ullah


