 Peter Smith
Peter Smith

⬤ Google has achieved a significant breakthrough in AI research as two unreleased versions of its upcoming Gemini model delivered top scores on the Hieroglyph benchmark. The models, internally called Snowbunny, set a new performance standard on a test specifically designed to measure lateral reasoning abilities across leading large language models.
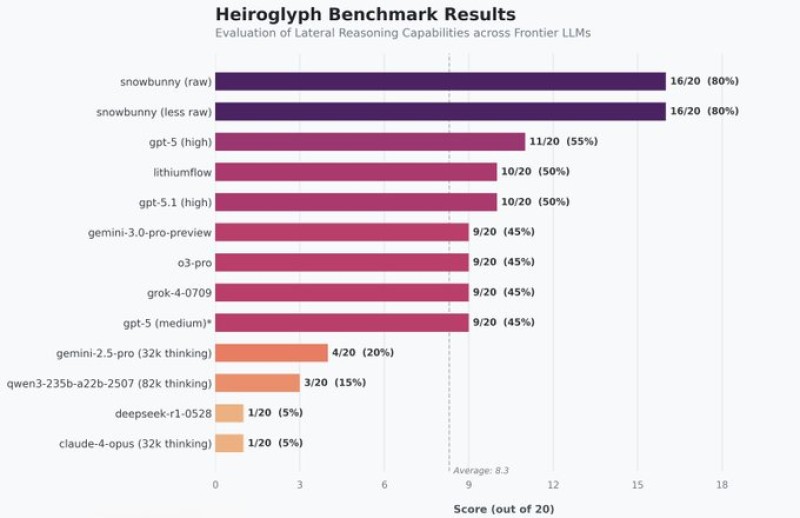
⬤ The Hieroglyph benchmark tests abstract thinking, non-linear problem solving, and the ability to make indirect connections—skills that go far beyond simple memorization or pattern recognition. Both Snowbunny versions scored 16 out of 20 (80%), significantly outperforming the competition. The next-best models only managed scores between 9 and 11 out of 20, while the benchmark's overall average sat around 8.3, showing a clear performance gap at the top.
⬤ Most well-known frontier models landed in the middle of the pack, scoring between 45% and 55%. Large-context and extended reasoning variants posted notably lower results. The fact that both Snowbunny configurations—raw and less-raw—achieved similar scores suggests this wasn't just narrow optimization but genuine reasoning strength across different test conditions.

⬤ These results matter because lateral reasoning is becoming a crucial differentiator for next-generation AI systems. Strong Hieroglyph scores indicate progress toward models that can handle novel tasks, complex instructions, and real-world ambiguity more effectively. As competition heats up among frontier AI developers, independent reasoning benchmarks are emerging as key indicators of where meaningful capability advantages exist and how future AI systems might evolve in advanced problem-solving domains.
 Peter Smith
Peter Smith


