 Saad Ullah
Saad Ullah

⬤ GLM-4.7 has taken the lead over GPT-5.1 in the latest Vending-Bench2 benchmark, according to Z.ai reports. The open-source model showed particularly strong results in long-horizon agentic tasks, proving its ability to handle complex operations that stretch over extended timeframes. This performance establishes GLM-4.7 as the current frontrunner among open-source AI models.
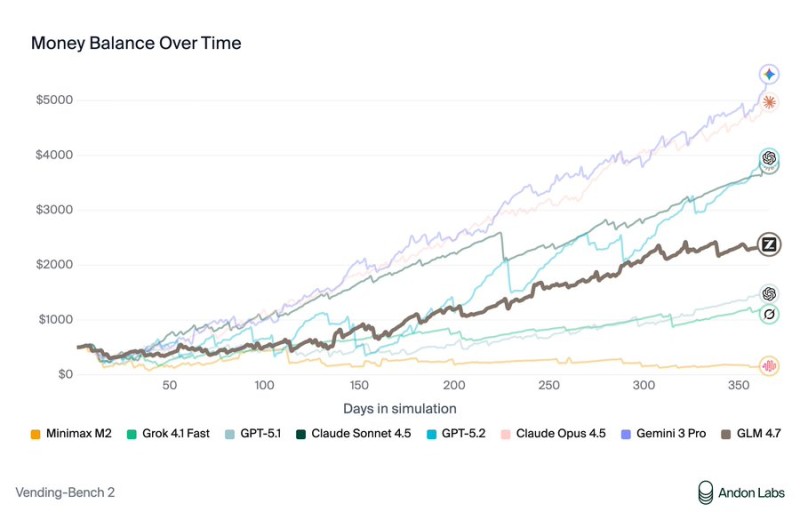
⬤ During the 350-day simulation measuring money balance progression, GLM-4.7 maintained a steady upward curve while competitors like GPT-5.1, Grok 4.1 Fast, and Claude Sonnet 4.5 showed inconsistent patterns. The model's ability to sustain performance over this extended period demonstrates its practical value for real-world applications requiring long-term reliability.
⬤ The benchmark revealed that while GPT-5.1 started strong, GLM-4.7's advantage became clear through its stable efficiency across the full testing period. This distinction highlights how models perform differently when evaluated over longer timeframes rather than brief snapshots, which could reshape how the industry approaches AI model testing.
⬤ GLM-4.7's success in Vending-Bench2 reflects a growing industry focus on scalable, sustainable AI performance rather than short-term benchmarks. As the leading open-source model in this evaluation, it sets a new standard that could influence future development priorities and push other teams to optimize for long-term consistency in their models.
 Saad Ullah
Saad Ullah


