 Alex Dudov
Alex Dudov

⬤ JPMorgan Asset Management (JPMAM) just dropped some eye-opening research showing that AI agents are getting way better at handling complex, multi-step tasks - but there's a catch. Top-tier models like Claude Opus 4.6, GPT-5.2 high, and Gemini 3 Pro can now power through tasks that used to be impossible for AI. The problem? These same systems frequently spit out wrong answers that sound totally convincing. Their chart called "AI agents can now do more than ever, but can you trust them?" lays out both the impressive progress and the worrying accuracy issues across different AI models.
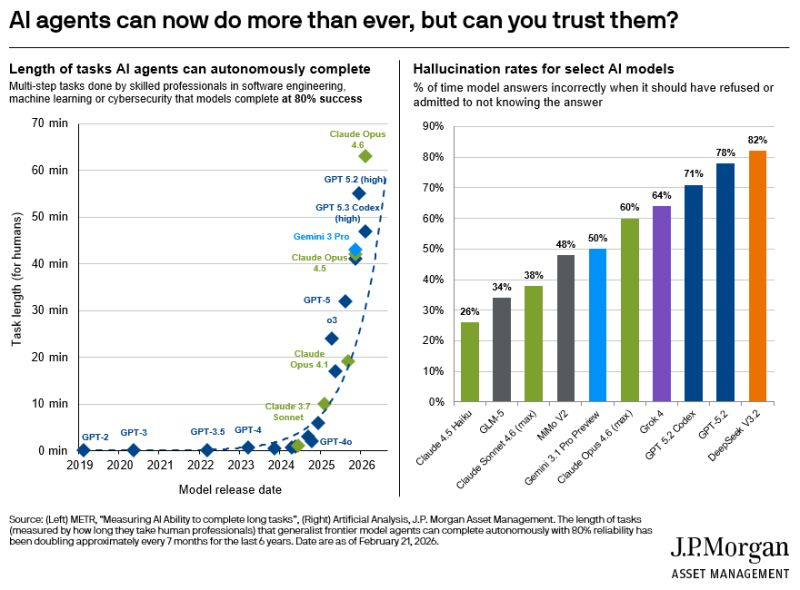
⬤ The data shows just how far we've come. Back in 2019, GPT-2 could barely handle quick, simple tasks. Fast forward to today, and models like Claude Opus 4.6 and GPT-5.2 high can tackle work that would take a human nearly an hour or more - all at around 80 percent reliability. This leap forward matters for the whole AI ecosystem. The 2025-2026 models are breaking through old limits in autonomous reasoning.
⬤ But here's where it gets messy. The hallucination rates - when AI makes up incorrect answers instead of admitting it doesn't know - are still pretty high. Some advanced models like GPT-5.2 Codex and Grok hit hallucination rates over 70 percent, with others pushing past 80 percent. Claude 3.5 Haiku does better at around 26 percent, but the overall picture shows a real trade-off between capability and accuracy.
⬤ JPMAM's findings highlight where AI development stands right now: these tools are becoming incredibly powerful, but they're not bulletproof. As Mike Zaccardi points out, "AI agents can now do more than ever, but can you trust them?" As companies integrate AI deeper into engineering, research, and data work, understanding these limitations will shape everything from deployment strategies to regulatory policy and future AI infrastructure investments.
 Alex Dudov
Alex Dudov


