 Peter Smith
Peter Smith

Long-context AI has long been a battlefield of diminishing returns. Most architectures fall apart well before the 1 million token mark, leaving developers to patch gaps with external retrieval systems. EverMind's Memory Sparse Attention (MSA) changes that calculus entirely, delivering consistent performance from 16K all the way to 100 million tokens.
How MSA Outperforms Qwen, DeepSeek, and Other Long-Context Rivals
Benchmark data tells a clear story. As context length climbs, models like Qwen variants and DeepSeek show steady score degradation. The MSA-4B model holds near the top of the chart throughout, recording less than a 9% accuracy drop even at extreme context lengths. OpenAI vs Anthropic: Long Context Model Performance Explained provides useful background on why competing architectures tend to degrade beyond the 256K to 1M token range.
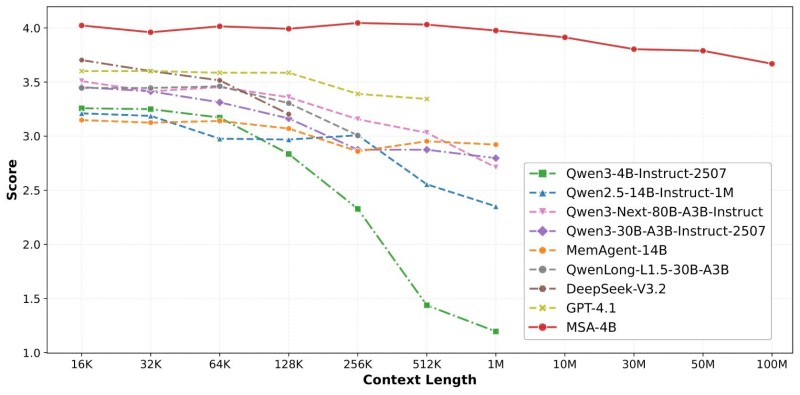
The architecture achieves this through three interlocking innovations: sparse attention with linear complexity, document-aware positional encoding, and a memory interleaving mechanism. Together, these allow models to maintain coherence across fragmented, distributed information without the overhead that typically slows traditional systems. Progress in this direction mirrors broader trends covered in AI Progress Accelerates: Models Now Complete Multihour Complex Tasks.
What MSA Means for AI Infrastructure and NVDA Demand
Retrieval-based workarounds and compressed attention methods have served as a band-aid for years. MSA makes a structural argument that memory should live inside the attention layer itself, not bolted on externally. The implications extend to hardware demand: as models become more efficient at processing massive contexts, the appetite for high-performance AI infrastructure could shift in meaningful ways. Broader architectural thinking behind this transition is explored in Agent World Model Points to Next AI Architecture Shift.
For enterprises dealing with legal documents, codebases, or multi-session research, a model that stays sharp at 100M tokens is not an incremental improvement. It is a different category of tool altogether.
 Peter Smith
Peter Smith


