 Saad Ullah
Saad Ullah

⬤ Codex CLI is the only terminal agent among the three tested that delivers results above the default Terminus 2 agent on the Terminal Bench evaluation. The chart shows a clear separation between Codex CLI and the other agents, with Claude Code and Gemini CLI both performing below the baseline reference line that represents Terminus 2.
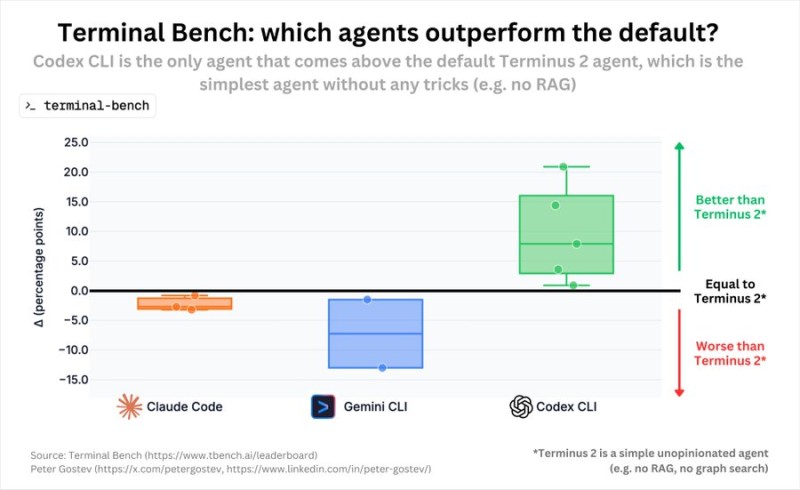
⬤ Looking at the visualization, Claude Code's distribution sits slightly below baseline, with most results falling between roughly -2 and -5 percentage points. Gemini CLI shows a wider and deeper spread, ranging from near zero down to approximately -15 percentage points, which points to more volatile and consistently weaker performance. Codex CLI, on the other hand, shows a fully positive distribution, with median performance well above zero and top results reaching close to the 20 percentage point range. The chart also notes that the Gemini CLI score for the Gemini 3 Pro model isn't available yet.
⬤ Terminal Bench measures agent performance on structured terminal tasks without enhancements like retrieval-augmented generation or graph search. Terminus 2 serves as a straightforward baseline agent in this setup, making it a solid benchmark for comparison. The fact that Codex CLI beats this baseline while other agents fall short really highlights the current capability gap across major command-line AI tools. These performance differences matter a lot given the growing emphasis on automation and reliability in terminal-based workflows.
⬤ This matters because benchmark performance increasingly shapes expectations around emerging AI systems. Differences in consistency, accuracy, and baseline-relative results influence broader assessments of tool maturity and readiness for real-world use. As more agents enter evaluation and benchmark datasets expand, these distinctions will likely help define the competitive landscape in the rapidly evolving AI tooling space.
 Saad Ullah
Saad Ullah


