 Saad Ullah
Saad Ullah

Abacus AI just grabbed the top spot on Terminal Bench 1.0, and it's doing something different from everyone else. Instead of betting everything on one model, they're running a hybrid setup that switches between Sonnet 4.5 and GPT-5 depending on what the task needs. The benchmark chart shows Abacus AI Desktop hitting 62.3%—a clear lead over every other coding agent out there.
Abacus AI Takes the Lead on Terminal Bench
The Terminal Bench 1.0 rankings put Abacus AI Desktop at 62.3%, with Ante trailing at 60.3% and Droid at 58.8%. Older coding agents are falling way behind: Codex (GPT-5) manages 42.8%, Claude Code (Opus) reaches 43.8%, and Claude Code (Sonnet-4) sits at 35.5%.
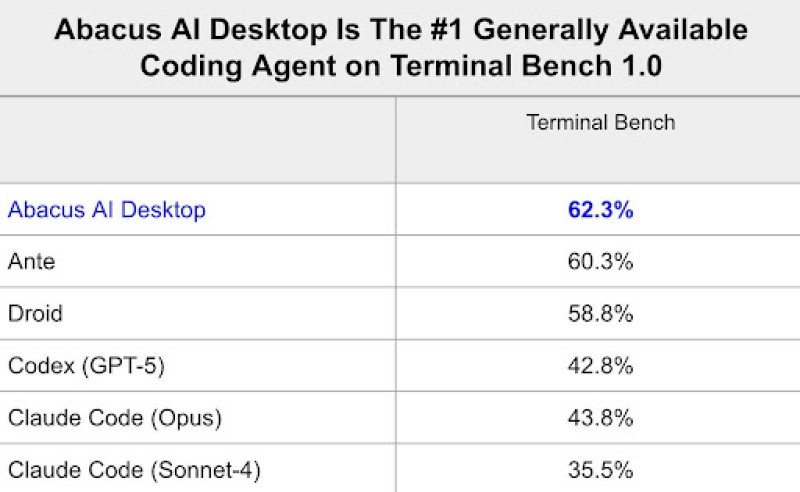
There's an interesting detail here—while the original post mentions Sonnet 4.5, the benchmark chart shows Claude Code (Sonnet-4). This probably means Abacus AI is running a newer Sonnet variant internally, even though the official Claude Code benchmarks still use the older version.
Why Abacus AI Is Pulling Ahead
Terminal Bench 1.0 doesn't mess around. It tests command-line tasks, debugging loops, multi-step reasoning, and how well agents handle automated tools. Abacus AI's strong showing isn't just about having powerful models—it's about smart orchestration that knows when to switch between them.
Here's what's giving Abacus the edge: dynamic routing between GPT-5 and Sonnet 4.5 based on what the task actually requires, solid task decomposition that prevents cascading failures, tight terminal integration for quick error correction, and constant updates that keep pushing performance higher.
Single-model agents like Claude Code or Codex can't match this flexibility, which is why they're scoring so much lower on varied coding tasks.
What This Means for the Industry
Abacus AI's rise points to where things are headed: coding agents are moving away from relying on one big model toward multi-model intelligence. As development work gets more complex, systems that can route tasks to the right model at the right time are showing real advantages.
The gap in these benchmarks is telling. Codex used to be the gold standard for code generation, but now it's sitting way below next-gen hybrid agents. That's not just an incremental improvement—it's a fundamental shift in how AI coding tools are built.
 Saad Ullah
Saad Ullah


