 Saad Ullah
Saad Ullah

⬤ VoxCPM just dropped as a fresh open-source text-to-speech system that's taking a different route to make synthetic voices sound more real. Instead of using the usual tokenization approach that most TTS models rely on, VoxCPM works directly with continuous audio. This means it skips the step where speech gets chopped up into discrete chunks, which often makes AI voices sound less natural.
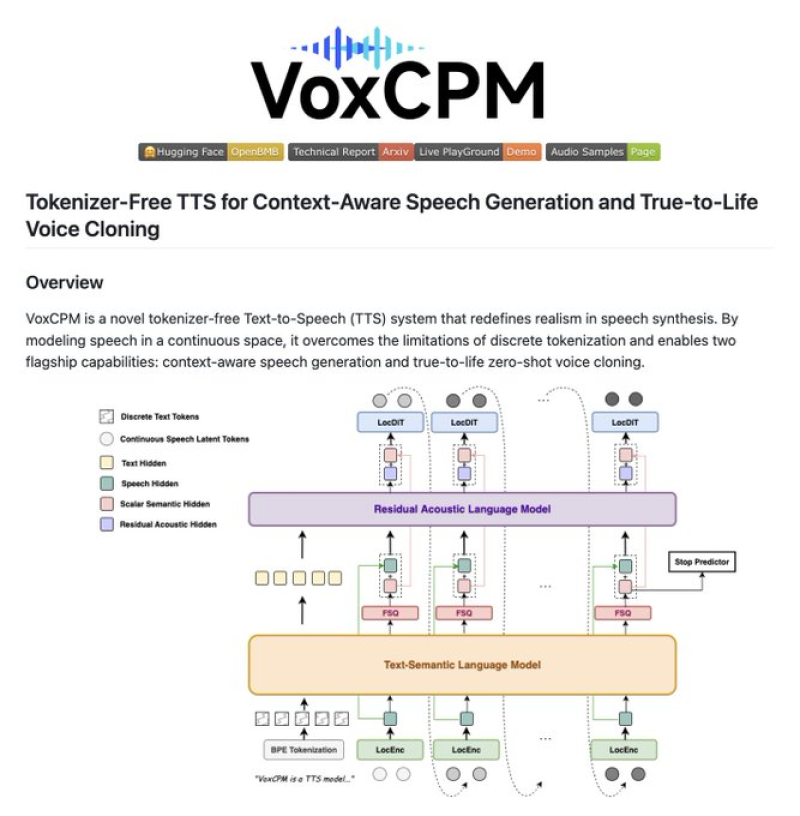
⬤ The system runs on an end-to-end diffusion autoregressive framework that generates speech without needing text or acoustic tokens. What this does is let VoxCPM figure out the right tone, emotion, and pacing straight from your text input—no manual tweaking needed. The voice cloning feature is particularly impressive: give it a five-second audio clip, and it'll pick up accent, rhythm, and emotional tone to recreate that voice.
⬤ VoxCPM was trained on roughly 1.8 million hours of bilingual audio covering English and Chinese. The current version 1.5 works at 44.1 kHz sampling rate with about 800 million parameters, which helps produce clearer, more lifelike audio. It also supports streaming synthesis, works with both full fine-tuning and LoRA methods, and comes with a straightforward Python interface for easy setup.
⬤ This release matters because it shows how TTS technology is moving toward systems that actually sound human and work in real situations. With its Apache 2.0 license, VoxCPM is ready for commercial use, which could speed up its adoption in voice assistants, content creation, accessibility tools, and interactive AI applications. As more people demand speech generation that genuinely sounds like a person talking, tokenizer-free approaches like VoxCPM might become the new standard for text-to-speech tech.
 Saad Ullah
Saad Ullah


