 Peter Smith
Peter Smith

⬤ Tencent's ARC team has developed Vision-Language Models that can reason across four dimensions—combining spatial awareness with temporal understanding. Their DSR Suite creates geometric question-answer pairs directly from video footage, then applies 4D reasoning through a Geometry Selection Module. This approach represents a fundamental shift in how AI systems interpret video content.
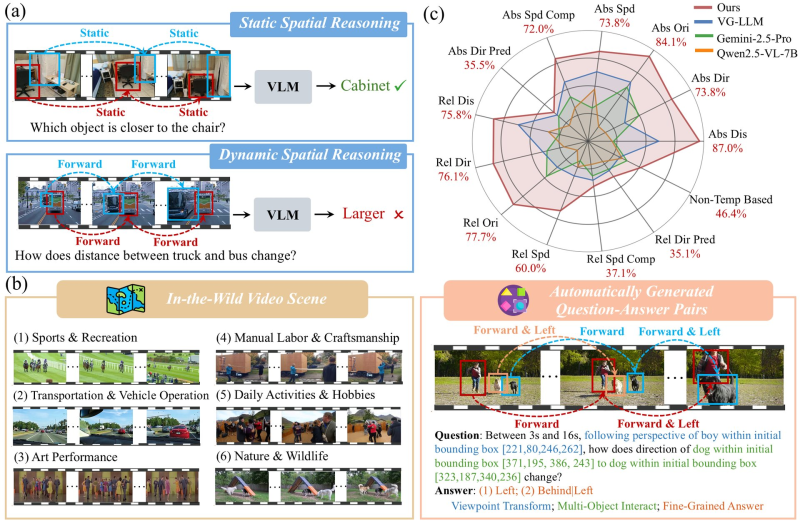
⬤ The team combined their Qwen2.5-VL-7B model with GSM to hit 58.9% accuracy on DSR-Bench testing, crushing baseline models by more than 20 percentage points. The system excels at tracking how objects move and change through space over time—something traditional video models struggle to grasp consistently.
⬤ What makes this advancement particularly valuable is that the model doesn't sacrifice general video understanding to gain 4D capabilities. Most models that add dimensional complexity lose ground on standard video tasks, but Tencent's system maintains broad video processing ability. This balance opens doors for practical applications in autonomous vehicles, robotics, and interactive AI systems.

⬤ The development signals real progress in video AI. Tencent has created a model that understands not just what's happening in a video, but how objects relate to each other in space as they move through time—a crucial capability for any system that needs to navigate or interact with the physical world.
 Peter Smith
Peter Smith


