 Marina Lyubimova
Marina Lyubimova

⬤ Google's Switch Transformers research is getting a second look after demonstrating that AI models could be trained up to seven times faster than traditional dense transformer architectures. The breakthrough happened back in 2022 but got overshadowed while the AI industry kept pouring resources into scaling dense transformer models. The research suggests that while companies like OpenAI continue throwing massive compute resources at model training, Google's approach offers a more efficient path to reach the same model quality with significantly less computational power.
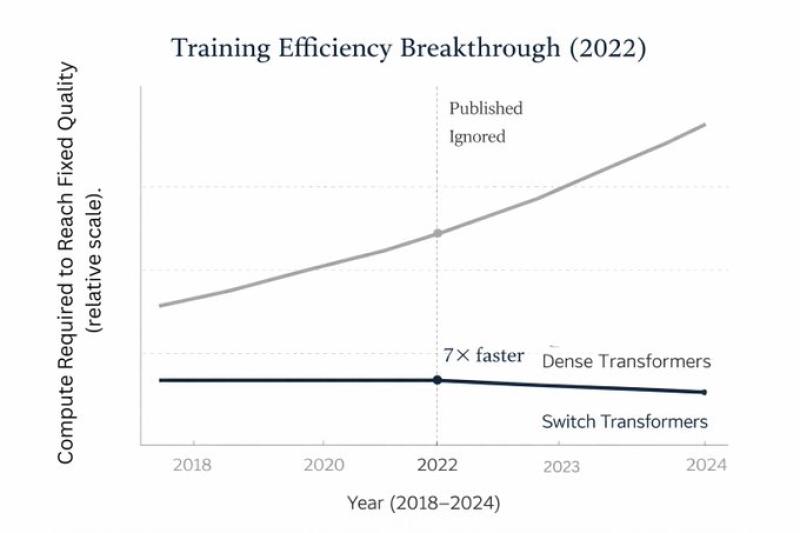
⬤ The data compares dense transformers against Switch Transformers from 2018 through 2024, measuring compute required to hit fixed quality benchmarks. Dense transformers show steadily climbing compute demands year after year, while the Switch Transformer line stays essentially flat over the same timeframe. The 2022 milestone marks where Switch Transformers achieved 7x faster efficiency, dramatically cutting compute needs while maintaining the same output quality as dense models.
⬤ This resurfaced discussion comes as AI compute costs increasingly dominate industry conversations. Switch Transformers have evolved from what many viewed as an "academic curiosity" into what could be a "production necessity," yet the architecture hasn't been widely adopted despite the research being public for years. The gap between published technical breakthroughs and actual industry implementation remains striking.

⬤ The implications are huge. AI compute demand now drives major financial and strategic decisions across tech, shaping capital spending, infrastructure buildouts, and competitive positioning. If Switch Transformers can genuinely slash compute requirements while preserving model quality, they could fundamentally alter the cost assumptions that underpin current AI business models. With Google behind the research, expect this debate over adoption to intensify.
 Marina Lyubimova
Marina Lyubimova


