 Saad Ullah
Saad Ullah

⬤ Researchers from Fudan University, the University of Washington, and the National University of Singapore have introduced AdaReasoner, a model treating tool usage as fluid reasoning capability rather than memorized sequence. The system applies reinforcement learning to dynamically select, sequence, adopt, or discard tools depending on task context. This approach aligns with broader industry shifts emphasizing context-driven AI architectures, as 95% of AI engineering now focuses on context systems.
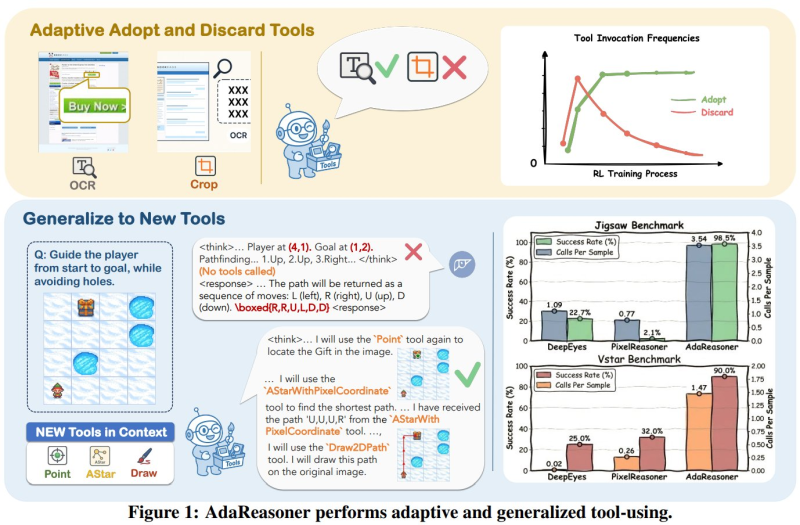
⬤ AdaReasoner's adaptive reinforcement learning loop allows tool invocation frequencies to evolve during training. Instead of repeatedly invoking static utilities, the model learns to use tools - OCR, cropping, coordinate detection, A* pathfinding, and drawing functions - only when they contribute to task success. On the Jigsaw benchmark, AdaReasoner achieves approximately 98.5% success rate, significantly outperforming DeepEyes and PixelReasoner. On the VStar benchmark, it posts results above 90%, demonstrating strong generalization and iterative reasoning accuracy. The growing competitiveness of reasoning-focused AI models reflects a wider research race in advanced systems, similar to how Alibaba's Qwen 3.5 hits 90 in math benchmarks.
⬤ A core innovation lies in AdaReasoner's ability to generalize to unfamiliar tools introduced within context. Rather than memorizing fixed pipelines, the model develops reasoning policy adapting to new utilities during inference. This strategy supports multi-step visual planning and structured tool orchestration across tasks requiring dynamic adjustment. The research emerges amid increasing academic output in AI innovation, particularly from leading institutions like Tsinghua University, filing over 1,000 AI patents annually.
⬤ The development underscores the importance of reinforcement learning-driven tool adaptation in next-generation multimodal systems. As visual reasoning benchmarks grow more demanding, models capable of dynamic orchestration rather than static scripting may help redefine performance standards in structured problem-solving environments.
 Saad Ullah
Saad Ullah


