 Saad Ullah
Saad Ullah

⬤ Fresh benchmark results comparing top language models show clear performance differences rooted in how these systems are built. Trinity-Large runs as an extremely sparse mixture-of-experts model—a 400B-parameter system with 256 experts but only four active per token. This design came together during an intense 30-day training window and delivers unusually fast inference. The benchmark chart stacks Trinity-Large against DeepSeek-V3 and GLM-4.7, measuring output throughput, total throughput, and time to first token.
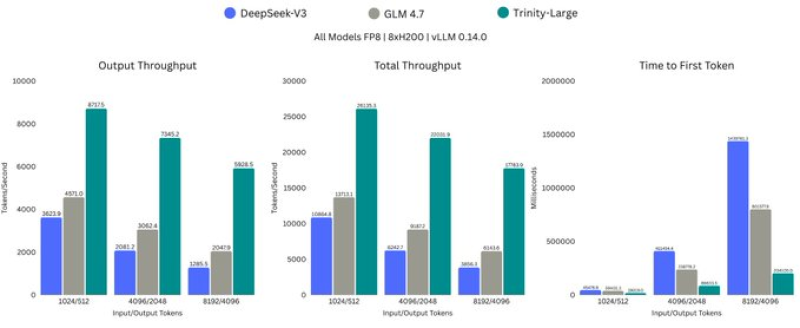
⬤ Trinity-Large dominates output throughput and total throughput across different input and output token setups. As sequence sizes grow, Trinity-Large consistently posts the highest tokens-per-second numbers, pulling away from the competition. Time-to-first-token results also show lower latency compared to DeepSeek-V3 and GLM-4.7, meaning faster initial responses when handling inference workloads. "Trinity-Large is an extremely sparse mixture-of-experts model, built as a 400B-parameter system with 256 experts and only four active per token," highlighting how aggressive sparsity translates directly into speed gains.
⬤ Several technical choices power this performance edge. Trinity-Large swaps out softmax routing for normalized sigmoid, boosting numerical stability in the router—a common trouble spot in MoE models. It uses an auxiliary-loss-free load balancing method similar to DeepSeek-V3 but adds momentum to keep expert bias from swinging wildly. The model also applies sequence-level load balancing loss to spread expert usage more evenly within sequences, plus a dedicated z-loss at the language model head to control logit growth and maintain stability.
⬤ These benchmarks matter because they prove architectural efficiency can unlock serious speed and responsiveness improvements. The data shows sparse MoE designs like Trinity-Large can hit strong inference performance even with tight training schedules. As competition heats up among large language models, comparisons like these spotlight how design decisions beyond raw parameter count are driving the next wave of model deployment and scale.
 Saad Ullah
Saad Ullah


