 Peter Smith
Peter Smith

⬤ LFM2.5-1.2B-Thinking just dropped on Hugging Face as a lightweight reasoning model built for speed and privacy. The model runs completely offline in roughly 900MB of memory—small enough for on-device deployment without touching cloud servers. It's designed to deliver quality reasoning outputs while keeping inference fast and the memory footprint tight.
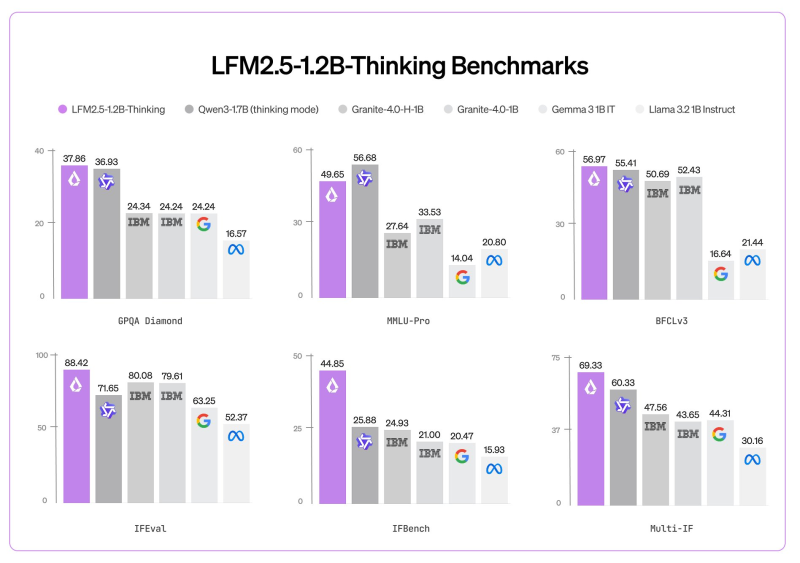
⬤ Benchmark scores show solid performance across reasoning tasks. The model hit 37.86 on GPQA Diamond and 49.65 on MMLU-Pro. On BFCLv3, it scored 56.97, putting it in competitive range with other compact models tested alongside it.
⬤ Instruction-following and multi-step reasoning benchmarks paint a similar picture. LFM2.5-1.2B-Thinking posted 88.42 on IFEval, 44.85 on IFBench, and 69.33 on Multi-IF. Those numbers show the model can handle diverse reasoning scenarios despite its size constraints.
⬤ This release reflects a bigger push toward efficient, edge-ready AI that prioritizes local deployment and privacy. As demand grows for reasoning models that run on personal devices, LFM2.5-1.2B-Thinking highlights how model efficiency improvements are driving real-world AI adoption strategies.
 Peter Smith
Peter Smith


