 Saad Ullah
Saad Ullah

⬤ A joint team from Shanghai Jiao Tong University, DP Technology, and the Chinese Academy of Sciences has unveiled Innovator-VL, a multimodal large language model built for scientific discovery and visual reasoning. Rather than scaling on massive opaque datasets, the project prioritizes a transparent, reproducible training pipeline - a notable departure from industry norm. The model handles scientific charts, diagrams, and complex visual content while staying competitive on general vision tasks.
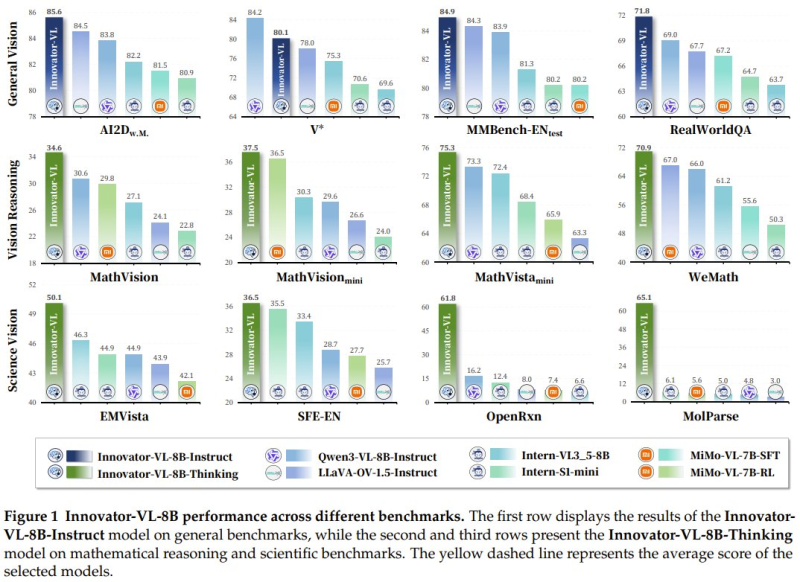
⬤ General vision benchmarks paint a strong picture. Innovator-VL recorded 85.6 on AI2D, outpacing several rival models in direct comparisons. It also reached approximately 84.9 on MMBench-EN-test, roughly 84 on the V* benchmark, and around 71.8 on RealWorldQA. These scores put Innovator-VL among the top-tier models in multimodal evaluation, with visual reasoning results comparable to GPT-5.4's ARC-AGI-2 performance.
⬤ The Innovator-VL-8B-Thinking variant pushes further into reasoning territory. On MathVision it scored about 34.6, with 37.5 on MathVision-mini and around 50.1 on EMVista. Science-specific tasks show even more promise: 61.8 on OpenRxn and 65.1 on MolParse - benchmarks that test chemistry diagram analysis and molecular parsing, areas where most general-purpose models still fall short.
⬤ What makes these numbers stand out is the training footprint. Innovator-VL achieved all of this on fewer than 5 million curated samples - a fraction of what comparable multimodal systems typically require. The team argues this validates a data-quality-first philosophy: careful curation beats sheer volume. This mirrors the efficiency-first trend seen in models like DeepSeek-V4Lite, which recently ranked 2nd among Chinese AI models.
 Saad Ullah
Saad Ullah


