 Marina Lyubimova
Marina Lyubimova

⬤ China's AI research community has been buzzing about an interesting technical relationship between DeepSeek's Conditional Memory and ByteDance Seed's Over-Encoding approach. These aren't the same technique wearing different labels—they're actually two separate evolutionary paths that tackle different fundamental problems in how large language models work.
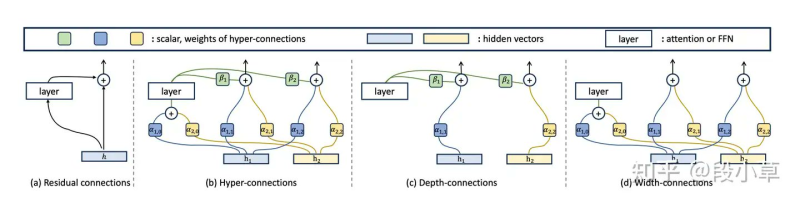
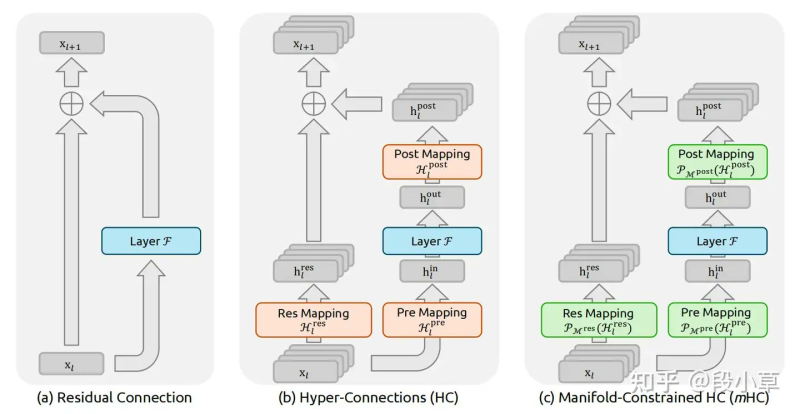
⬤ The architecture story starts with residual connections, the breakthrough that made today's deep networks possible by letting information skip past layers that might otherwise block it. ByteDance took this concept further with hyper-connections, which run multiple parallel information streams through each layer with learnable weights controlling how they combine. You get better performance without the usual computational penalty. DeepSeek refined this with manifold-constrained hyper-connections—essentially adding mathematical guardrails that keep signals stable as they flow through the network. "These constraints help prevent instability such as gradient explosion or vanishing," allowing the architecture to scale deeper without falling apart.
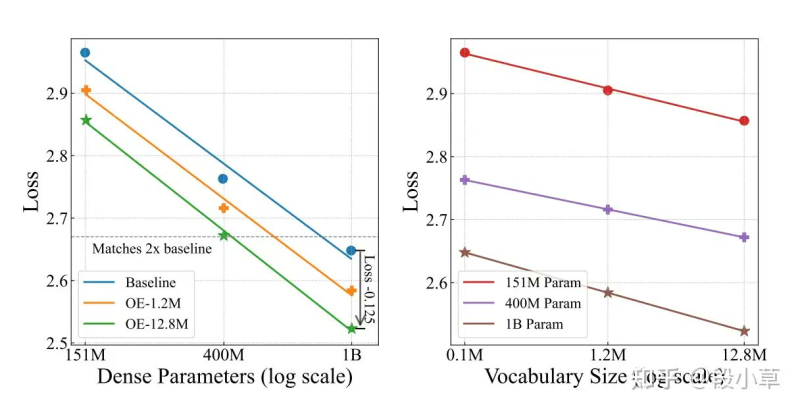
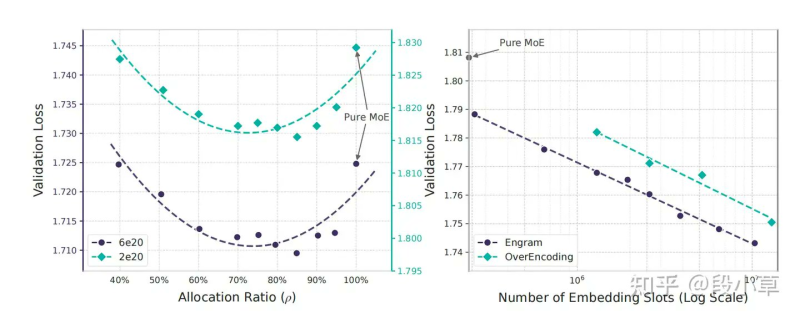
⬤ The memory side evolved along similar lines. Old-school n-gram systems were basically static dictionaries—fast but inflexible. ByteDance Seed's Over-Encoding flipped the script by embedding massive n-gram vocabularies directly into the model's input space, essentially swapping vocabulary size for parameter count. Their experiments showed smaller models with huge vocabularies matching the performance of much larger dense models. DeepSeek's Engram mechanism took this concept and made it smarter by adding conditional gating—the system only activates relevant memory based on what it's currently processing, maintaining O(1) lookup speed while keeping memory footprint minimal. The clever part? Memory can live outside expensive GPU memory, cutting hardware costs significantly.
⬤ What emerges isn't a competition but a convergence. Hyper-connections show how widening information pathways boosts capacity, while manifold constraints solve the stability problems that creates. Over-Encoding proves memory scaling can replace parameter scaling, and Engram makes that memory context-aware. The bigger picture reveals where large model research is heading—architectural stability and memory efficiency now matter just as much as throwing more parameters at the problem.
 Marina Lyubimova
Marina Lyubimova


