 Eseandre Mordi
Eseandre Mordi

Speed matters in AI interaction. xAI's recent performance metrics show their Grok models responding to prompts in under 7 milliseconds, making conversations feel almost instantaneous. This breakthrough in latency reduction transforms how users experience AI-powered tools.
Grok Models Break 7ms Response Barrier
xAI dropped a service status update that caught everyone's attention—their Grok models are blazingly fast. Mario Nawfal shared the metrics showing several versions starting to generate responses in less than 7 milliseconds after receiving a prompt.
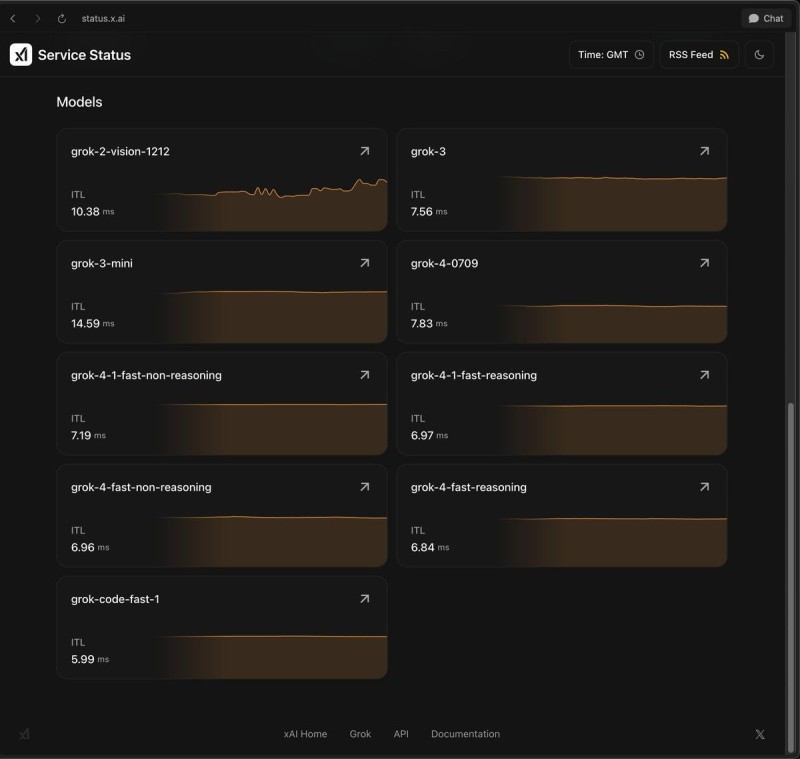
The dashboard reveals impressive numbers. The grok-code-fast-1 variant clocks in at approximately 5.99 milliseconds, while grok-4-fast-reasoning follows closely at 6.84 ms. Other versions like grok-4-fast-non-reasoning and grok-4-1-fast-reasoning hover in the same 6-7 ms sweet spot. These measurements track initial token latency—basically how fast the model begins talking back to you.
Performance Across Different Configurations
Even the slightly slower models stay competitive. The grok-3 version runs at about 7.56 ms, grok-4-0709 hits near 7.83 ms, while grok-2-vision-1212 comes in around 10.38 ms. The grok-3-mini sits at roughly 14.59 milliseconds.
These measurements represent initial token latency, indicating how quickly a model starts responding.
What This Means for Users
This speed revolution matters for real-world use. When you're chatting with an AI, every millisecond counts. Sub-7ms latency means the delay between hitting enter and seeing the first words appear becomes virtually unnoticeable. You get near-instant feedback, making interactions feel natural and fluid instead of clunky and delayed.
The Technical Edge
xAI's achievement demonstrates consistent performance across different model configurations. Whether you're using specialized code models or reasoning-focused variants, response times stay impressively low. This consistency suggests solid infrastructure optimization rather than one-off performance spikes.
The update showcases xAI's commitment to reducing friction in AI interactions. Fast initial responses keep conversations flowing, prevent user frustration, and make AI tools feel more responsive and reliable during everyday usage.
 Eseandre Mordi
Eseandre Mordi


