 Usman Salis
Usman Salis

● According to a report by AshutoshShrivastava, Reddit filed a lawsuit against Perplexity AI in New York federal court. The suit alleges that Perplexity and its partners—Oxylabs and SerpApi—scraped Reddit's content illegally to train AI systems. Reddit claims Perplexity got around its security protections and accessed data without authorization, breaking the platform's terms of service.
● Reddit says this hurts its new data licensing business, which already has agreements with Google and OpenAI—but not Perplexity. The company wants financial damages and a court order stopping Perplexity from using its data for AI training.
● Perplexity fired back with a public statement on Reddit itself, calling the lawsuit "a sad example of what happens when public data becomes a big part of a public company's business model." The startup emphasized it doesn't train foundation models, suggesting Reddit is overreacting. Perplexity believes Reddit's growing dependence on selling data access—especially as some AI companies pull back from partnerships—has made the platform more aggressive about protecting its content.
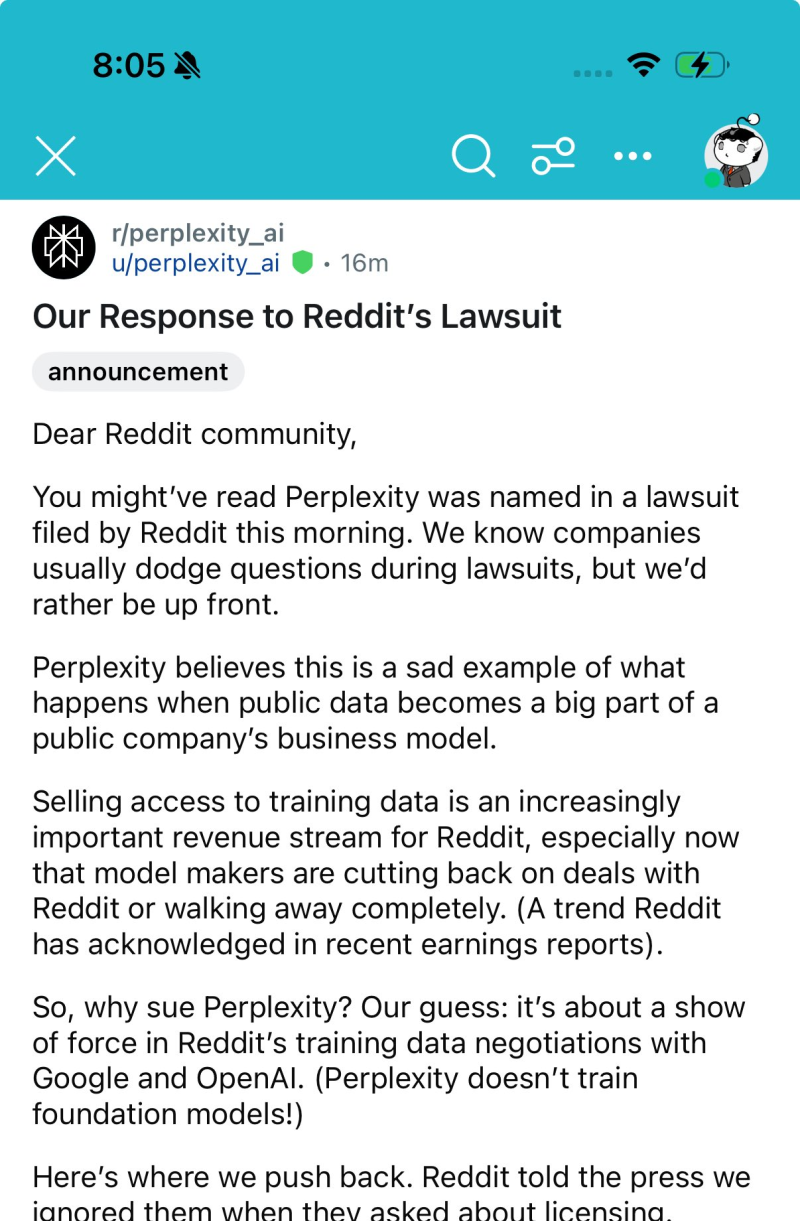
● "Selling access to training data has become an important revenue stream for Reddit," Perplexity wrote, hinting the lawsuit might be a negotiating tactic in Reddit's deals with Google and OpenAI. The company also denied ignoring Reddit's licensing outreach, calling the case "a power move, not a legal necessity."
● Industry watchers say the lawsuit shows the deepening tension between AI developers and data platforms over who owns and profits from online content. As AI models increasingly rely on massive amounts of web data, this case could shape how publicly available information gets used in the AI economy.
 Usman Salis
Usman Salis


