 Saad Ullah
Saad Ullah

● Raiza Martin recently put two AI agents to the test with a simple but revealing challenge: automate her daily routine of checking her daughter's school grades and assignments, then create a tracking table. She pitted OpenAI's Atlas against Perplexity's Comet, and the results weren't even close.
● Both agents understood what needed to be done, but execution told a different story. Comet stumbled through navigation, worked sluggishly, and botched the tracking table. Atlas breezed through the entire task flawlessly. For anyone thinking about using AI for repetitive online work, these small errors matter—they waste time and mess up your data when you're counting on automation to just work.
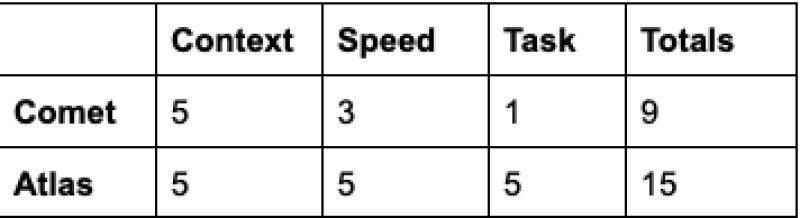
● Martin's scoring made the gap crystal clear. Comet managed 5 points for understanding context, 3 for speed, and just 1 for actually completing the task correctly—9 points total. Atlas scored perfect 5s across the board for 15 points. That's not just a technical win; it's the kind of reliability difference that determines whether businesses actually adopt these tools or abandon them after frustrating trials.
● What makes this particularly interesting is how Atlas handled obstacles. When a "missing assignments" filter didn't work, it didn't just give up—it figured out another path forward, much like a person would. This adaptive problem-solving represents a real leap in agentic AI, which is quickly becoming one of the most competitive areas in artificial intelligence.
● In the rapidly evolving world of AI capabilities, this head-to-head positions Atlas as the current frontrunner for agent-based tasks—a glimpse of where practical automation is actually headed.
 Saad Ullah
Saad Ullah


