 Eseandre Mordi
Eseandre Mordi

⬤ The AI community's been buzzing after early performance data dropped comparing MiniMax M2.1 and GLM-4.7. These initial results come straight from the model makers themselves, so take them with a grain of salt. The comparison looks at two popular benchmarks—SWE-bench Verified and Terminal Bench 2.0—giving us a first glimpse at how these models stack up against each other.
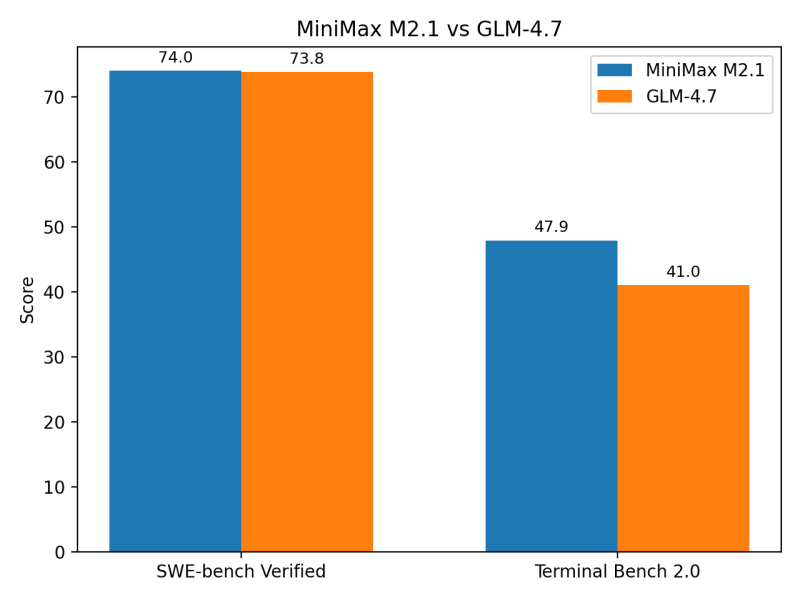
⬤ On SWE-bench Verified, it's basically a tie. MiniMax M2.1 scored 74.0 while GLM-4.7 came in at 73.8—just a 0.2-point difference. For practical purposes, they're running even on software engineering tasks. Neither model shows any real advantage here based on what we're seeing.
⬤ Terminal Bench 2.0 tells a different story. MiniMax M2.1 hit 47.9 compared to GLM-4.7's 41.0, opening up a noticeable gap. This suggests MiniMax handles terminal-based tasks—think command execution and structured interactions—more effectively. That's a pretty clear separation compared to their near-identical SWE-bench performance. Still, remember these are vendor numbers, not independent verification.

⬤ Why does this matter? These benchmarks help position where each model stands in the crowded LLM space. But without third-party testing, we can't draw hard conclusions yet. Once independent evaluations roll out, we'll get a clearer picture of how these models actually perform in real-world scenarios—which might shift the current narrative built on these early figures.
 Eseandre Mordi
Eseandre Mordi


