 Peter Smith
Peter Smith

⬤ Z.ai just dropped GLM-4.7, their newest open-source language model that's showing real improvements over the previous GLM-4.6 version. The upgrade isn't just about technical benchmarks—it's also making waves in chat quality, creative writing, and role-play scenarios. But the numbers tell the most interesting story here.
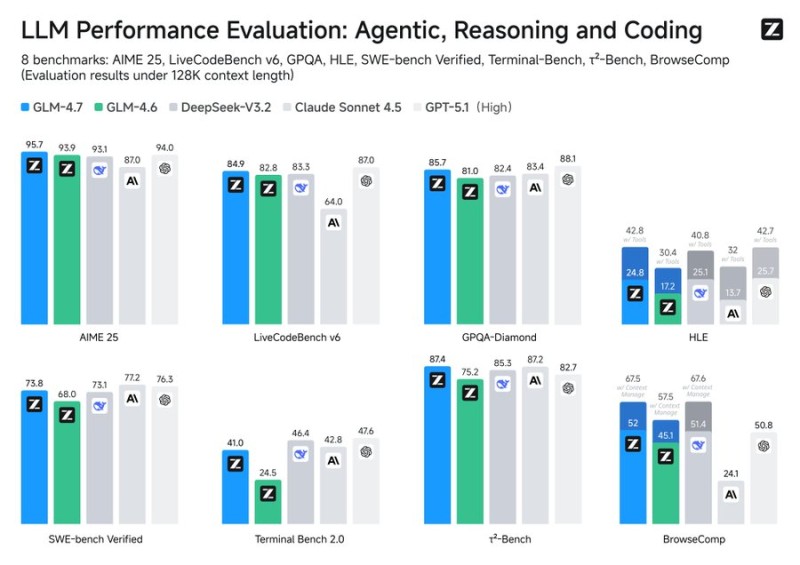
⬤ The benchmark comparison puts GLM-4.7 head-to-head with GLM-4.6 and other popular models across eight different tests: AIME 25, LiveCodeBench v6, GPQA-Diamond, SWE-bench Verified, Terminal-Bench, τ²-Bench, and BrowseComp. Everything's measured at 128K context length. When you look at coding-focused benchmarks like LiveCodeBench v6 and SWE-bench Verified, GLM-4.7 consistently beats its predecessor, showing better code generation and more reliable problem-solving.
⬤ The reasoning and agentic evaluations show steady progress too. GLM-4.7 pulls ahead in GPQA-Diamond and τ²-Bench, proving it can handle complex reasoning better than before. Tool-use performance got a boost as well, with stronger results in benchmarks testing multi-step execution and external tool interaction. While some tasks show bigger jumps than others, the overall trend points to meaningful advancement across the board.
⬤ What makes this release significant is how it highlights the speed of open-source AI development. Benchmark leadership keeps changing with each new release, and GLM-4.7's improvements in coding, reasoning, and tool usage open up more practical applications for research and development teams. As open-source models continue narrowing the gap with proprietary options, updates like this one could shift how companies think about capability, flexibility, and transparency when choosing their AI infrastructure.
 Peter Smith
Peter Smith


