 Saad Ullah
Saad Ullah

A small coding mistake just sparked a big conversation in AI circles. Epoch AI, the research group behind the widely-used Epoch Capabilities Index (ECI), found that their benchmarking system had been accidentally downgrading GPT-5's "high reasoning" mode to "medium" during tests. Once they fixed it, the results were surprising: GPT-5 (high) scored only slightly better than GPT-5 (medium)—and both ended up with the same overall ECI score. It's a reminder that even the best evaluation systems can stumble, and that measuring AI intelligence is trickier than it looks.
What Happened and Why It Matters
In a tweet, Epoch AI explained that a bug in their code had been quietly mislabeling GPT-5's reasoning tier, skewing its test results. After correcting it, GPT-5 (high) showed a small bump in performance—but not enough to pull ahead of the medium version. Both now sit at around 150 points on the ECI scale, compared to Claude 3.5 Sonnet's baseline of 130.
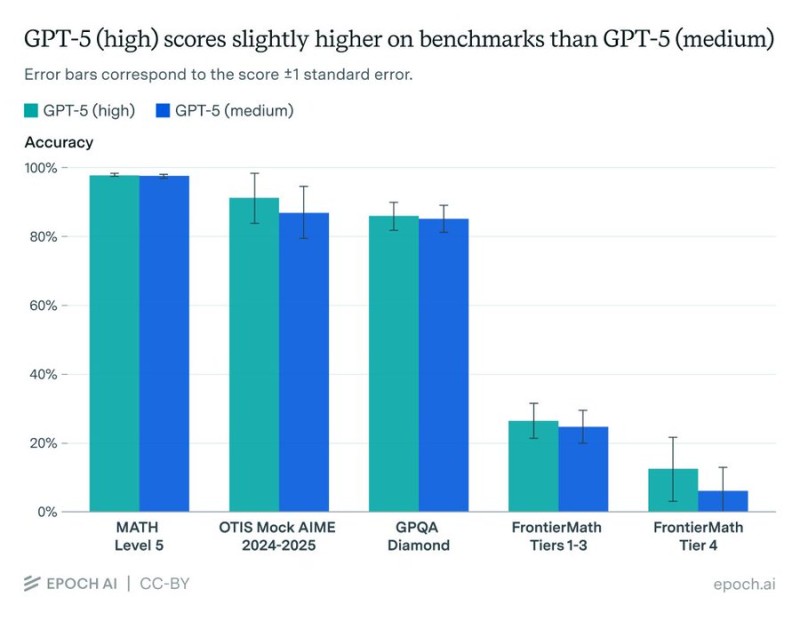
This matters for a few key reasons:
- Benchmark reliability – Even top-tier testing systems can have blind spots. A small bug changed how one of the world's most advanced AI models was being evaluated.
- Reasoning levels questioned – If "high" and "medium" reasoning modes perform almost identically, it suggests current benchmarks might not capture what reasoning really means—or that the extra compute doesn't pay off much.
- Trust in the ecosystem – Benchmarks influence everything from academic research to buying decisions. When bugs slip through, they can reshape how we compare leading AI models.
The Bigger Picture
The ECI works like an IQ test for AI, pulling together scores from dozens of tests on logic, coding, math, and language. It's meant to give a single, clean number for comparing models. But this incident shows how fragile that process can be—and how much trust we place in systems that aren't always foolproof.
The good news? Epoch AI was transparent about the mistake and shared their code publicly. That kind of openness is exactly what the field needs as benchmarks become more influential. The lesson for developers and companies is clear: don't rely blindly on leaderboard scores. Test models in your own context, and look beyond the numbers.
For now, the takeaway is simple: GPT-5's "high" and "medium" reasoning modes are functionally tied. Developers can probably stick with the medium tier and save on compute costs without losing capability. And as benchmarking evolves, we'll likely see more focus on real-world performance—like how models handle multi-turn conversations, tool use, or tasks under load—rather than static test scores.
In the end, this bug is a useful reminder that measuring AI intelligence is still a work in progress. Performance matters, but so does how we measure it—and whether we can trust those measurements in the first place.
 Saad Ullah
Saad Ullah


