 Marina Lyubimova
Marina Lyubimova

⬤ Recent benchmark results reveal how the newest AI models perform when faced with demanding science problems. OpenAI's ChatGPT-5.2 Pro took first place - answering 77.1 % of the FrontierScience-Olympiad questions correctly. The test was built to stretch every system with analytical work that demands authentic scientific thought.
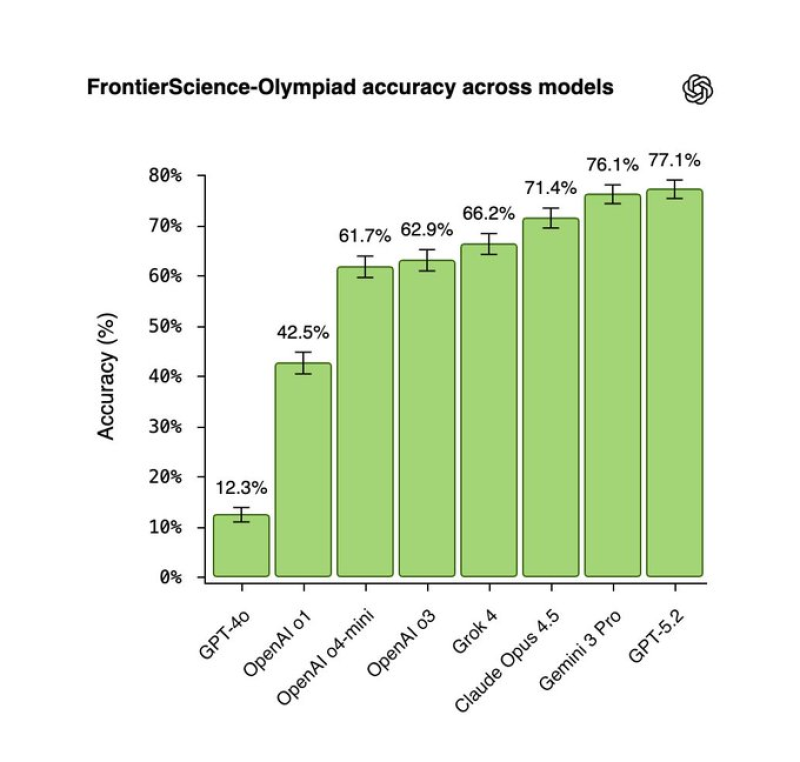
⬤ The remaining scores form a clear staircase. Gemini 3 Pro reached 76.1 %, only one point behind the leader. Claude Opus 4.5 landed at 71.4 %. After that the numbers fall away - Grok-4 achieved 66.2 %, OpenAI o3 62.9 % and o4-mini 61.7 %. Older models trail by a wide margin - o1 stopped at 42.5 % and GPT-4o managed just 12.3 %. The distance between generations is striking.
Day-to-day AI use now feels similar on every major platform, but real separation appears when the work turns to science plus research.
⬤ ChatGPT-5.2 Pro does not merely post the highest figure - it constructs and tests scientific hypotheses more reliably than its rivals. Gemini besides Claude still give strong general purpose service - yet OpenAI has pulled ahead on tasks that meet research standards.

⬤ The figures carry weight beyond prestige. Training costs keep rising and large leaps in ability are harder to secure. The company that leads in scientific reasoning will probably secure enterprise research contracts, university alliances but also institutional licences. The benchmark confirms that frontier models continue to advance quickly and it signals that skill in science is turning into the decisive factor in the next stage of AI competition.
 Marina Lyubimova
Marina Lyubimova


