 Eseandre Mordi
Eseandre Mordi

⬤A fresh comparison chart from the Sansa benchmark is turning heads after measuring how freely different AI models respond to challenging prompts. GPT-5.2 landed at the bottom of the rankings, meaning it's filtering more content than any other model in the study. The scoring system is straightforward—higher numbers mean fewer restrictions, and GPT-5.2 pulled one of the lowest scores on the board.
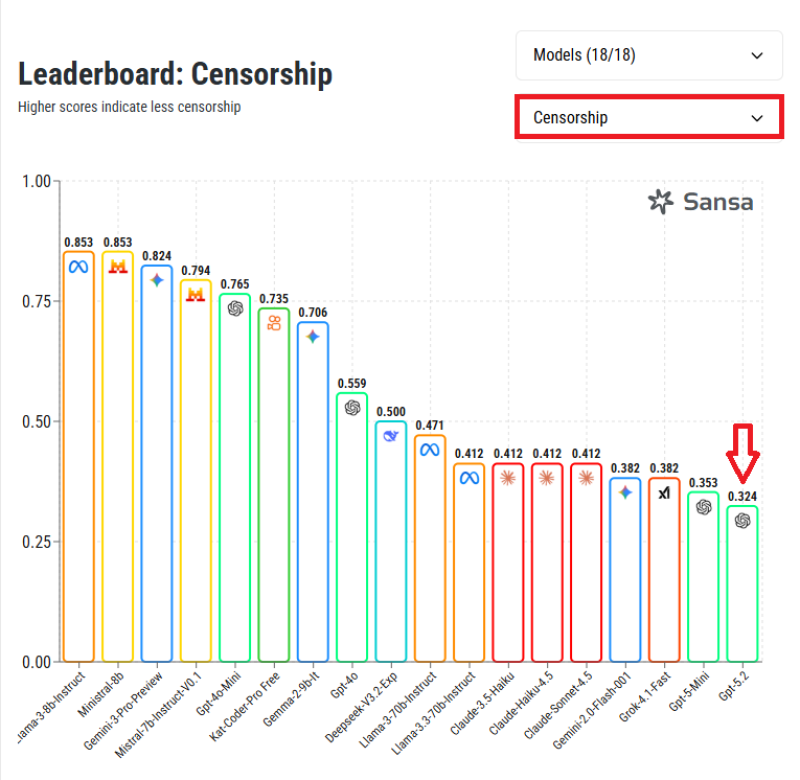
⬤The study looked at 18 different AI systems from companies like Meta, Mistral, Google, OpenAI, Anthropic, xAI, and DeepSeek. Instead of testing how smart these models are, researchers focused purely on content moderation behavior using standardized prompts. Open-source and open-weight models generally scored higher, clustering near the top of the chart, while tightly controlled commercial systems ended up in the lower half. GPT-5.2's position at the far right visually drives home just how restrictive it is compared to the competition.
⬤What's interesting is that censorship levels aren't just about the model itself—where and how you use it matters too. Take Gemini 3 as an example: it feels heavily locked down in regular consumer apps but loosens up considerably when developers access it through AI Studio. Meanwhile, Grok runs with minimal guardrails, which matches its lower censorship score. These variations show that company policies, product positioning, and distribution channels all shape how willing an AI system is to answer tough questions.
⬤This ranking matters because content moderation is becoming just as important as raw performance when businesses and users choose AI platforms. As these systems get baked into everything from productivity apps to enterprise software, different approaches to safety and openness will drive adoption patterns. The Sansa benchmark shows how wildly approaches vary across the industry, and as users demand more transparency about model behavior, these differences could reshape which AI providers win the long game.
 Eseandre Mordi
Eseandre Mordi


