 Peter Smith
Peter Smith
⬤ GPT-5.2 landed at 16th place with a 73.5% total score in the Dubesors LLM Benchmark's latest rankings. The benchmark evaluates over 250 large language models using a unified scoring system that combines multiple performance metrics into one comprehensive score.
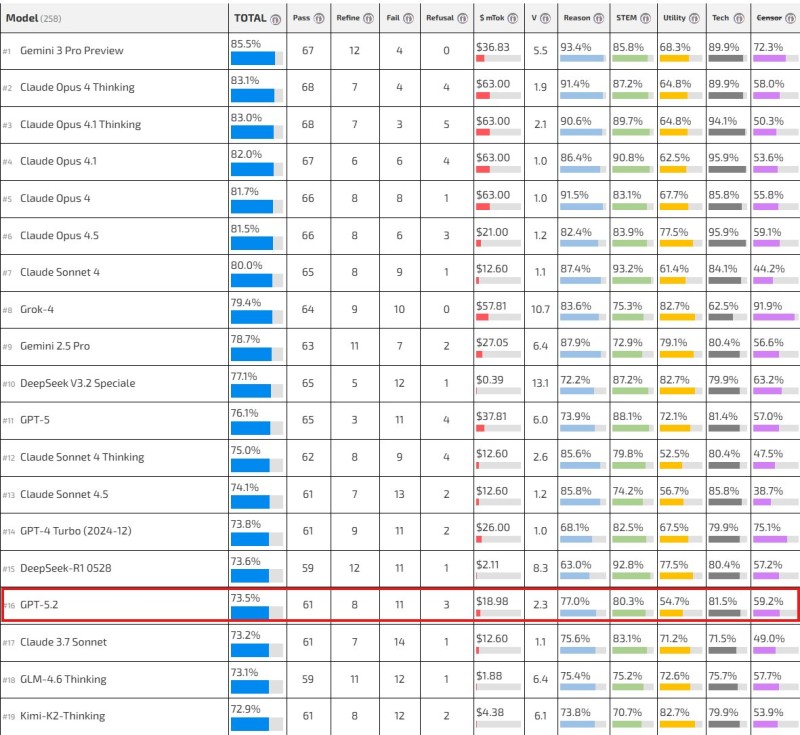
⬤ The model sits in the middle tier, trailing Gemini and Claude variants while staying ahead of numerous lower-ranked competitors. Performance metrics tracked include pass rates, refinement capabilities, failure rates, refusal handling, token costs, and specialized categories like reasoning, STEM proficiency, utility, technical performance, and censorship management.
⬤ Rankings in this range show tight clustering, with small percentage gaps separating neighboring positions. GPT-5.2 demonstrates well-rounded capabilities across categories rather than excelling in any particular area. The current snapshot reflects its standing among evaluated models at this point in time.

⬤ The 16th-place finish highlights the intense competition in LLM development, where small improvements and performance tradeoffs can dramatically shift rankings as new models continuously enter the benchmark.
 Peter Smith
Peter Smith


