 Saad Ullah
Saad Ullah

⬤ OpenAI just dropped fresh audio model snapshots for its Realtime API, bringing some serious improvements to how well these systems handle transcription, speech, and real-time commands. The latest release tackles two of the biggest headaches in AI audio: hallucinations and error rates. According to internal testing, the new models show measurable gains across the board.
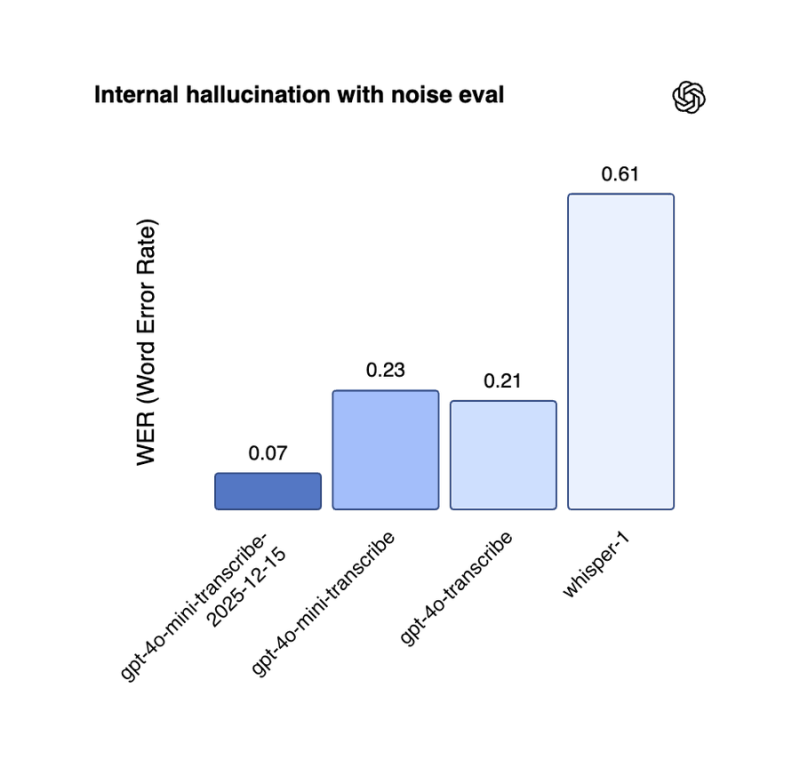
⬤ The standout performer is gpt-4o-mini-transcribe-2025-12-15, which cuts hallucinations by a massive 89% compared to the older whisper-1 model when dealing with noisy audio. Internal benchmarks show the new transcription model hitting a 0.07 Word Error Rate, absolutely crushing whisper-1's 0.61 score. That's a game-changer for anyone trying to get reliable transcriptions in less-than-perfect audio conditions.
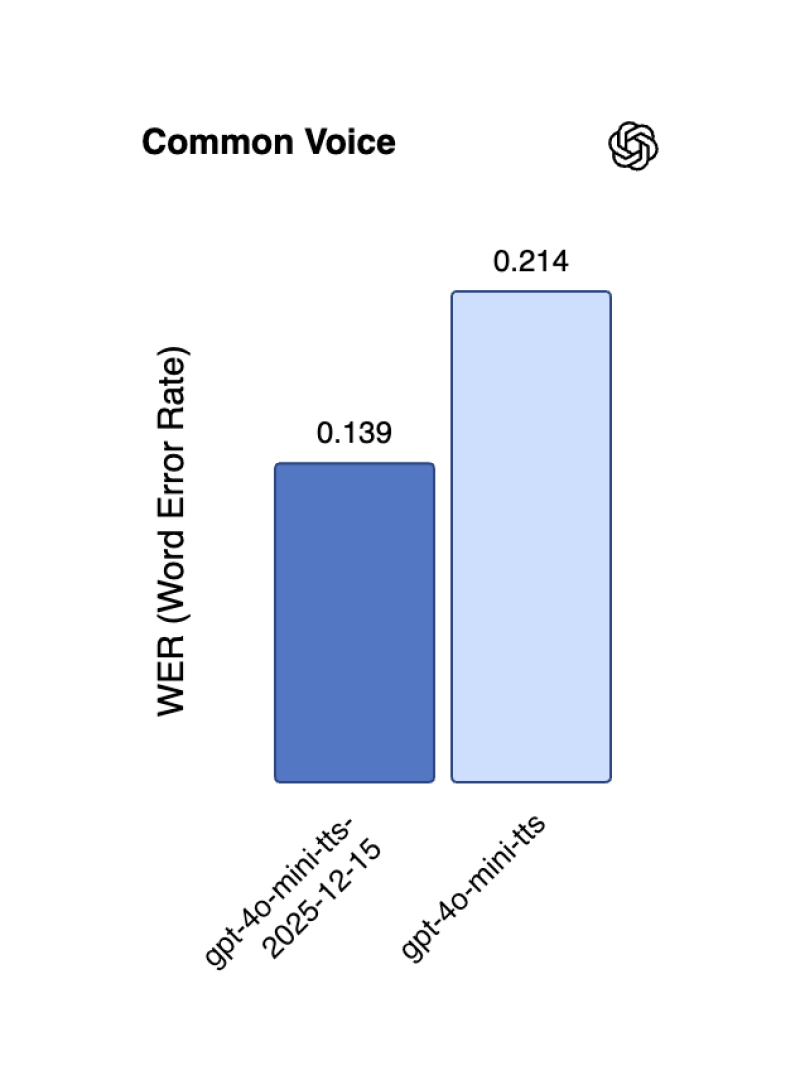
⬤ On the text-to-speech side, gpt-4o-mini-tts-2025-12-15 brings a 35% drop in word errors based on Common Voice testing. The data shows it clocking in at 0.139 WER versus the previous version's 0.214, meaning clearer pronunciation and more consistent speech quality across different voice samples.
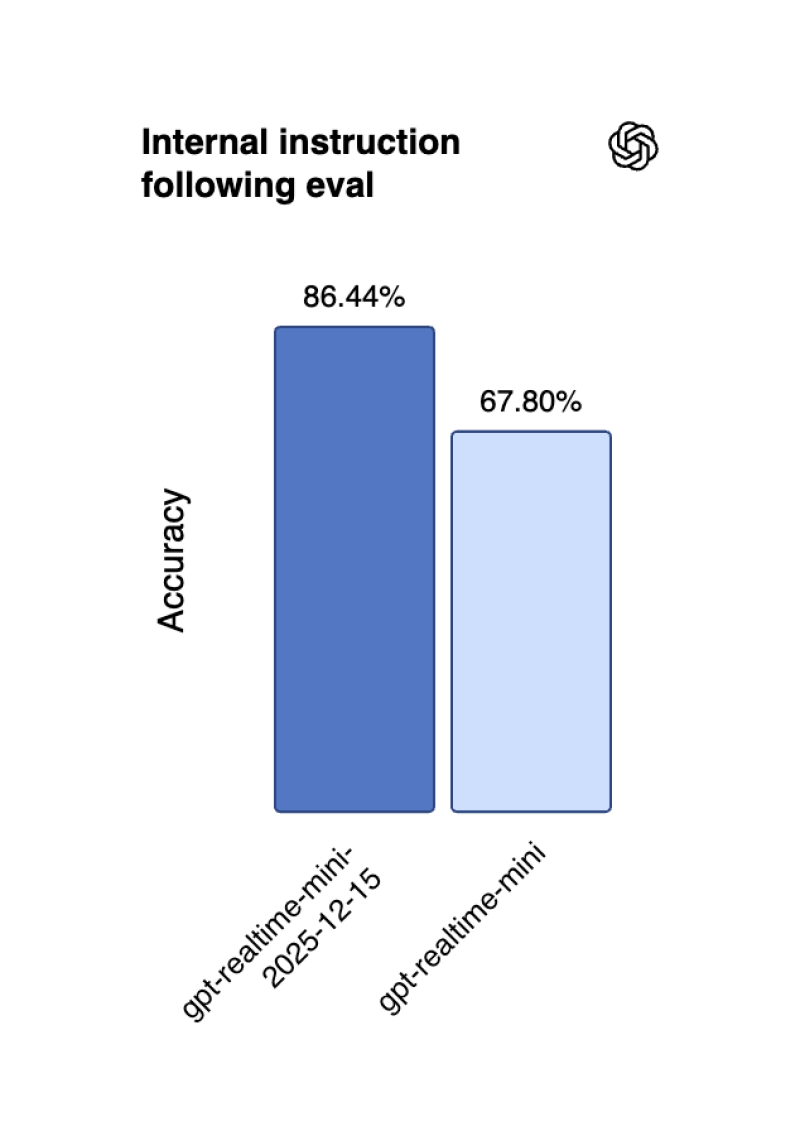
⬤ The real-time interaction model, gpt-realtime-mini-2025-12-15, jumped from 67.80% to 86.44% in instruction-following accuracy. OpenAI's internal numbers show a 22% improvement in following instructions and a 13% boost in function calling performance, making it significantly more reliable for live AI applications.
⬤ These upgrades point to OpenAI's commitment to building more trustworthy audio systems. By driving down errors in transcription, speech generation, and instruction handling, the new Realtime API snapshots set higher expectations for voice interfaces, interactive assistants, and real-time AI tools.
 Saad Ullah
Saad Ullah


