 Saad Ullah
Saad Ullah

⬤ Fresh research on SonicMoE is making waves in AI circles after showing impressive efficiency gains for mixture-of-experts models. The paper comes from Tri Dao, the researcher behind FlashAttention, and introduces a tile-aware routing technique designed to make sparse MoE execution work better. The results speak for themselves: SonicMoE pushes MoE kernel throughput up to 1.86x higher while slashing activation memory per layer by around 45% on Nvidia H100 GPUs.
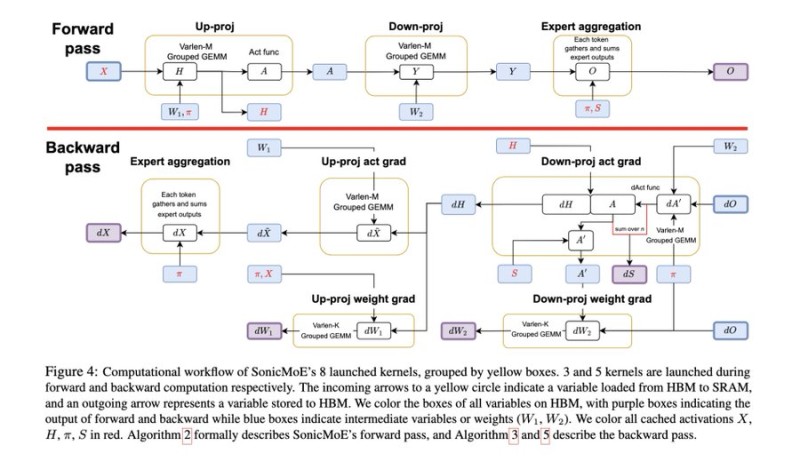
⬤ SonicMoE works by reorganizing how experts handle routing and matrix operations to match GPU tile sizes more naturally. This cuts down on the padding waste that usually happens when tokens get unevenly distributed across experts in sparse MoE models. The approach improves how GPUs actually use their resources without changing the model architecture itself—just making the existing setup run smarter.
⬤ What makes this particularly useful is the memory savings. On H100 GPUs, SonicMoE gets more out of grouped GEMM operations while reducing the memory footprint from cached activations. For large-scale training and inference, where memory constraints often become the bottleneck, this 45% reduction in activation memory opens up real possibilities for scaling. The streamlined gradient computation during backward passes adds to the throughput improvements across the board.

⬤ This matters because mixture-of-experts architectures are becoming the go-to method for scaling large language models without exploding compute costs. As models keep getting bigger, squeezing better routing efficiency and memory usage out of existing hardware becomes essential for actually deploying these systems. SonicMoE shows how smart software optimizations can unlock serious performance gains on hardware that's already widely deployed—potentially shaping how the industry approaches large-scale AI infrastructure moving forward.
 Saad Ullah
Saad Ullah


