 Usman Salis
Usman Salis
⬤ Fresh analysis breaks down the economics of improving LLM performance, showing two distinct paths to boost accuracy by 5 percent. Companies can either invest more in upfront training or scale up inference compute during actual use. Charts demonstrate how both approaches deliver accuracy gains, but the real question comes down to which one makes financial sense over the long haul.
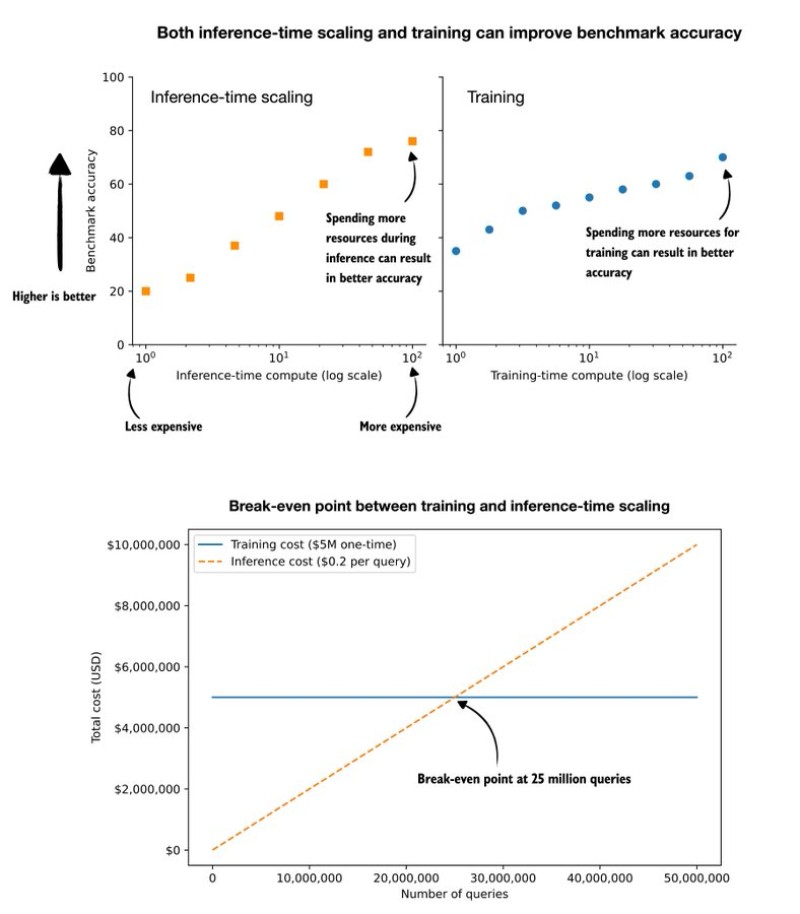
⬤ The math is straightforward: spending $5 million once on training versus paying an extra $0.20 per query for enhanced inference. Training hits your budget immediately, while inference costs grow with every user interaction. The pivotal moment happens at exactly 25 million queries, where the cumulative inference expenses match that one-time training investment. Run fewer queries than that, and extended training doesn't pay off. Go beyond it, and inference becomes the more expensive choice.
⬤ Translating this into real-world usage, a platform with 7,000 daily active users making ten queries each would hit that 25 million threshold in just one year. The data also shows that stacking both training and inference improvements together can push accuracy gains well past that 5 percent baseline, opening up hybrid optimization strategies.
⬤ This framework gives teams a concrete way to map compute spending against actual deployment patterns. Knowing exactly when training investment beats inference scaling, and where that equation flips, shapes everything from product roadmaps to infrastructure budgets. The numbers make it clear: how you allocate compute resources fundamentally determines both performance outcomes and long-term costs across an LLM's operational lifetime.
 Usman Salis
Usman Salis


