 Peter Smith
Peter Smith

The latest wave of advanced AI models keeps stirring up heated conversations across the tech world, and Google's DeepThink lineup has landed right in the middle of it all. Recently, developers and AI researchers have been calling out a troubling pattern: Google keeps showing off incredible benchmark numbers while keeping the actual models locked away from most users. This issue flared up again when a detailed benchmark comparison chart started circulating online, showing just how powerful these models are—and how out of reach they remain.
The Spark That Started the Fire
A recent social media post from a prominent AI analyst shed light on the frustrating situation around Gemini 2.5 DeepThink and the newer Gemini 3 DeepThink. Despite their jaw-dropping performance scores, both models are essentially unavailable to the broader developer community. Gemini 2.5 DeepThink even snagged a gold medal at the IMO 2025 mathematics competition, yet it's still locked behind Ultra-tier Google subscriptions with no public API in sight. Whether Gemini 3 DeepThink will follow the same restrictive path isn't clear yet.
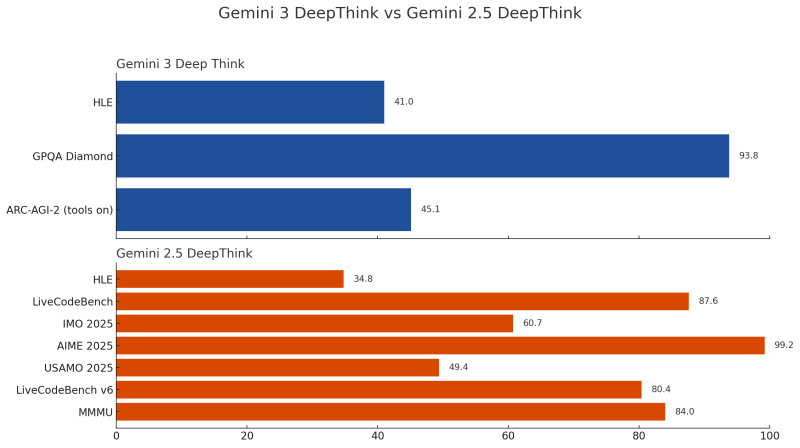
The post included a side-by-side benchmark chart comparing both model generations, and the data backs up everything people have been saying: Google's DeepThink models are producing world-beating results, but developers can't actually get their hands on them to test or build with them.
Breaking Down the Numbers
The benchmark chart reveals two distinct model profiles, each excelling in different areas:
- Gemini 3 DeepThink: GPQA Diamond 93.8 (elite graduate-level scientific reasoning), ARC-AGI-2 45.1 (abstract reasoning), HLE 41.0 (high-level logic)
- Gemini 2.5 DeepThink: AIME 2025 99.2 (near-perfect math), LiveCodeBench 87.6 (code reasoning), MMMU 84.0 (multimodal understanding), USAMO 2025 49.4 (olympiad math), LiveCodeBench v6 80.4, HLE 34.8, IMO 2025 60.7
These numbers paint a picture of two incredibly capable systems with slightly different strengths, but the same frustrating access problem.
Why Google Might Be Keeping Things Locked Down
Industry watchers have a few theories about Google's tight-fisted approach:
First, there are genuine safety concerns. Models with powerful reasoning abilities can generate complex, multi-step plans that could potentially be misused if widely available. Second, the computational costs appear to be massive. DeepThink variants seem to require enormous amounts of processing power, making widespread deployment prohibitively expensive. Third, these long-chain reasoning systems often need specific prompting techniques or extended context windows to work reliably, which might mean they're not quite stable enough for general release. Finally, Google might still be running internal evaluations to make sure the models perform consistently across different use cases before opening the floodgates.
That said, this strategy creates a sharp contrast with competitors like OpenAI and Anthropic, who typically release new models alongside accessible APIs that developers can actually use right away.
Why the Developer Community Is Getting Frustrated
The AI industry runs on transparency and testability, and benchmark-only releases create real problems. When developers can't independently verify the claims, they're forced to take Google's word for it. Without an API, these models can't be integrated into actual applications, making them essentially useless for real-world projects. Only Ultra-tier subscribers get to experiment with the technology, creating an uneven playing field where most developers are left on the sidelines. Even after winning legitimate competitions like IMO 2025, Gemini 2.5 DeepThink remains mostly a showcase piece rather than a practical tool.
The end result is a community that respects the impressive numbers but can't actually depend on the systems that produced them.
 Peter Smith
Peter Smith


