 Alex Dudov
Alex Dudov

⬤ GLM-4.7 just claimed the top spot among open-weights models for agentic AI applications, and new benchmark data shows why choosing the right provider matters more than ever. The model sits at #1 in the Intelligence Index for open-weights options, beating out DeepSeek V3.2 and Kimi K2 Thinking. But here's the thing—performance swings wildly depending on who's running your inference. The comparison chart breaks down how providers stack up on output speed versus cost per million tokens, and the spread is massive.
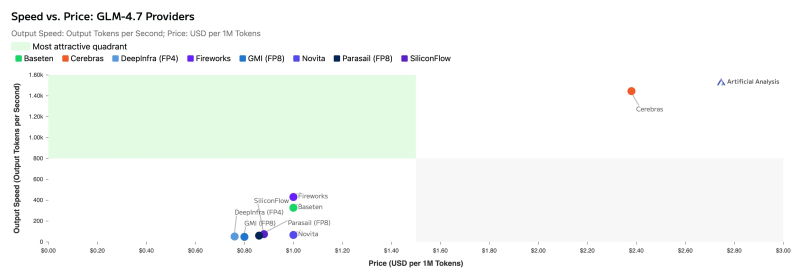
⬤ Speed tells the first part of the story. Cerebras absolutely crushes it with roughly 1,445 output tokens per second—leaving GPU providers in the dust, though you'll pay premium rates for that performance. On the GPU side, Fireworks leads the pack at around 430 tokens per second, with Baseten close behind at approximately 327 tokens per second. The rest of the field—SiliconFlow, DeepInfra, GMI, Parasail, and Novita—clusters way lower on throughput, creating a huge performance gap across the market.
⬤ Pricing flips the competitive picture completely. DeepInfra comes in as the cheapest option using blended input-output token ratios, with GMI and SiliconFlow right on its heels. Several providers sweeten the deal with cached input token discounts, which matters big time for agentic workflows that loop through similar contexts repeatedly. Most providers support up to 200k token context windows, though Cerebras and Parasail cap out smaller while still offering solid capacity.

⬤ Why this matters: GLM-4.7 logs the highest token usage of any model in the Intelligence Index, especially in agentic scenarios where continuous reasoning and tool calling dominate. As companies scale up agentic AI deployments, provider differences in speed, latency, and pricing are becoming make-or-break factors. The right infrastructure choice directly impacts operating costs, how fast your agents respond, and whether your system can scale when demand spikes.
 Alex Dudov
Alex Dudov


