 Peter Smith
Peter Smith

⬤ NVIDIA's Blackwell architecture swept every MLPerf Training v5.1 benchmark, claiming the fastest training times across the board and cementing the company's lead in AI compute. As developers scale up to larger models and test new architectures, demand for training compute is accelerating rapidly, pushing innovation across the entire AI stack at breakneck speed.
⬤ The surge in GPU demand faces headwinds from proposed tax changes that could make high-density data centers more expensive to run. Smaller AI labs might face serious trouble—potential bankruptcies, hiring freezes, or brain drain to countries with better tax environments. These policy risks collide directly with the industry's need for bigger GPU clusters and faster training cycles.
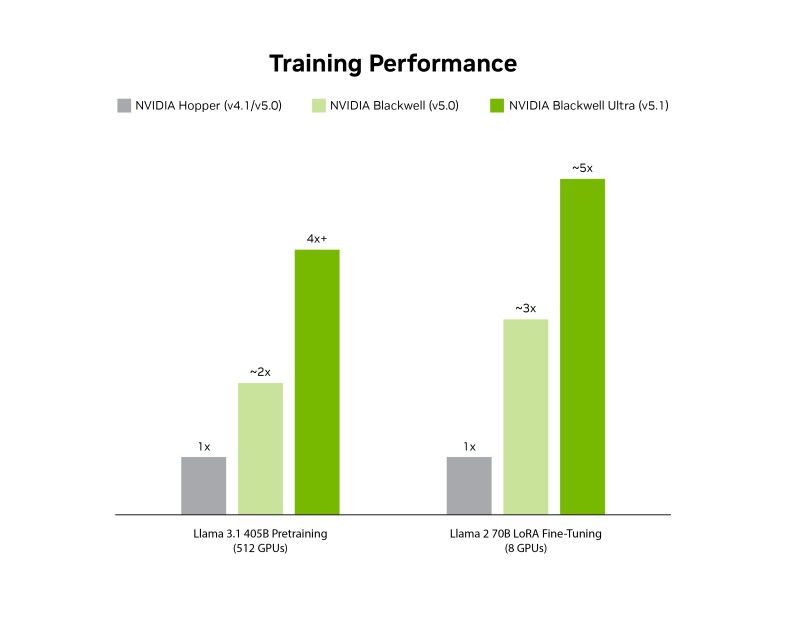
⬤ The latest benchmarks show Blackwell Ultra's massive leap forward: over 4× faster at pretraining Llama 3.1 405B versus the previous Hopper generation, and roughly 5× faster at LoRA fine-tuning on Llama 2 70B using just eight GPUs. Even standard Blackwell chips deliver 2-3× improvements. NVIDIA also submitted a record 5,120 Blackwell GPUs—more than double the previous round—while maintaining strong scaling efficiency.
⬤ With Blackwell Ultra now positioned as one of the most powerful AI training solutions on the market, the industry faces a pivotal moment. The combination of breakthrough performance, massive cluster scaling, and looming regulatory pressure could determine whether companies can keep training frontier models in the coming years.
 Peter Smith
Peter Smith


