 Victoria Bazir
Victoria Bazir

⬤ A team from Tsinghua University, Aalto University, Li Auto, and Infinigence-AI has developed MARSHAL, a framework that uses self-play to teach large language models strategic reasoning. The system trains LLMs to handle complex multi-agent problems by evaluating each decision and keeping the training process stable. It's built to make AI better at strategic thinking in challenging environments.
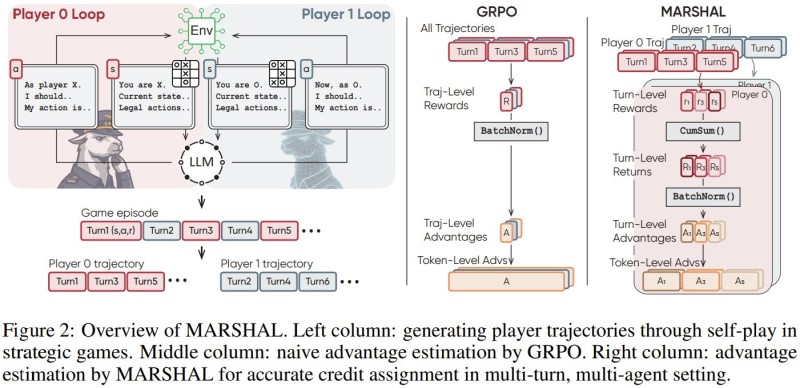
⬤ Running on the Qwen3-4B model, MARSHAL beats earlier versions by up to 28.7% in new game scenarios. The self-play approach lets the AI practice and get better across different situations without needing human oversight. This creates a level of strategic thinking that outperforms what came before, pushing AI decision-making forward.
⬤ The framework's game-based training carries over to other tests too. MARSHAL shows a 10.0% improvement on the AIME benchmark and 6.6% better performance on GPQA-Diamond. These gains prove the model works beyond just gaming tasks, making it useful for real-world problems. The combination of stable training and stronger reasoning marks real progress in AI development.

⬤ MARSHAL represents a major leap in LLM capabilities. By strengthening strategic decision-making and improving how well models apply their skills across different tasks, the framework could significantly upgrade AI performance in practical applications. As demand grows for intelligent systems that can tackle complex challenges, MARSHAL positions itself as a key tool for next-generation AI technology.
 Victoria Bazir
Victoria Bazir


