 Saad Ullah
Saad Ullah
The latest LiveBench rankings have sparked discussion across the AI community after new results revealed a surprising performance profile for Moonshot AI's Kimi K2 Thinking model. Despite landing far below top-tier models in the overall ranking, Kimi demonstrates exceptional strength in one of the most important real-world skill categories: instruction following.
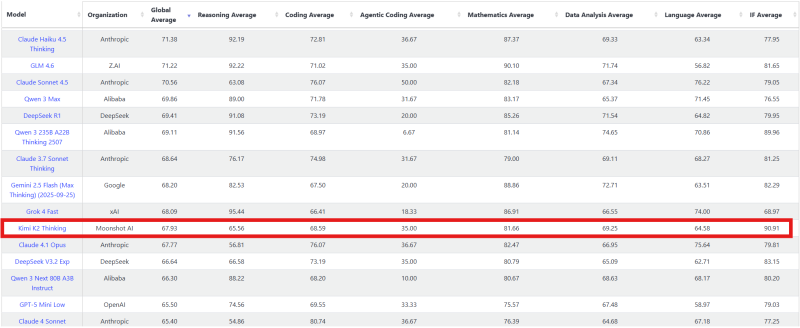
Recent data highlighted this unique contrast, noting that while Kimi K2 Thinking ranks 24th overall on LiveBench, it rises dramatically to 2nd place in the instruction-following subcategory. The chart confirms this split clearly, revealing a model with standout alignment capabilities but significant weaknesses in logical reasoning tasks.
Kimi K2 Overall Performance
The LiveBench data shows Kimi K2 Thinking with a Global Average score of 67.93, placing it below high-performing models such as Claude Haiku 4.5 (71.38), GLM 4.6 (71.22), Claude Sonnet 4.5 (70.56), Qwen 3 Max (69.86), and DeepSeek R1 (69.41).
However, this position doesn't tell the whole story. Kimi delivers far better results in instruction-following tests, outperforming nearly all other major LLMs.
Reasoning Weakness Drags Down Rankings
Kimi's low overall rank comes mainly from its weaker performance in the reasoning category. The model's Reasoning Average sits at 65.56—substantially lower than leaders like Claude Haiku 4.5 (92.19), GLM 4.6 (92.22), and DeepSeek R1 (91.08). Kimi struggles particularly with the Web of Lies and Zebra Puzzle benchmarks, two of LiveBench's toughest tests involving multi-step logic, constraint reasoning, and deception detection.
Performance Across Categories
Beyond reasoning, Kimi shows balanced but not leading performance across other areas:
- Coding: 68.59
- Agentic Coding: 35.00
- Mathematics: 81.66
- Data Analysis: 69.25
- Language: 64.58
- Instruction Following: 90.91 (2nd place)
Kimi K2 Thinking's performance pattern highlights an important shift in the AI landscape. Many real-world applications—assistants, workflow tools, content agents—depend more on instruction accuracy than abstract logic puzzles. By excelling in user-aligned tasks even while trailing in reasoning, Kimi positions itself as a strong option for practical AI deployments rather than benchmark-dominated competitions.
As benchmarking frameworks evolve and specialization becomes more common, models like Kimi K2 Thinking show that overall rank doesn't always reflect true practical value. Its 24th-place global position contrasts sharply with its elite status in instruction following—proving that strength in applied tasks may matter more than ever.
 Saad Ullah
Saad Ullah


