 Usman Salis
Usman Salis

⬤ HySparse takes a different approach to AI attention mechanisms by mixing full and sparse attention layers throughout its architecture. The full attention layers work as guides, deciding which tokens need the most computational focus, while enabling the entire model to share its key-value cache more efficiently.
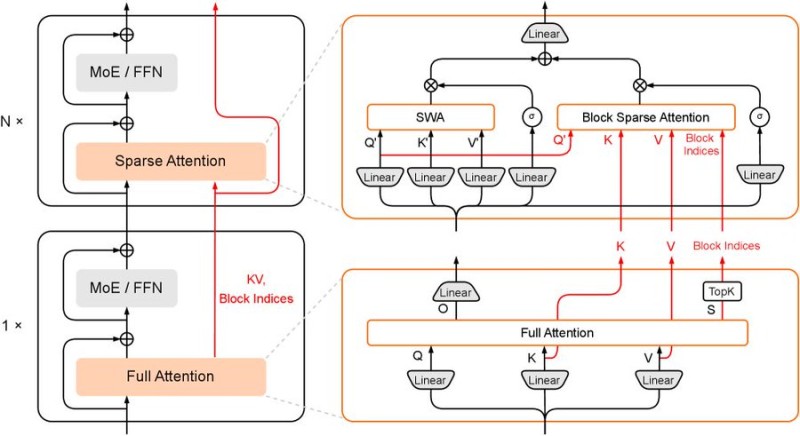
⬤ The system alternates between complete attention processing and reduced attention handling during inference. Full attention layers identify the critical tokens that need dense computation, while sparse attention manages everything else in the sequence. This back-and-forth structure keeps the model accurate without overwhelming memory resources.
⬤ The real breakthrough comes from selective token processing combined with shared KV cache operations. By choosing which tokens get full attention and which can work with sparse processing, HySparse achieves roughly 10x memory reduction compared to standard baseline methods. The architecture doesn't just save memory—it actually performs better than those baselines too.

⬤ HySparse represents a practical solution for running larger AI models with limited resources. The design proves that combining accuracy-focused computation with resource efficiency isn't just possible—it can actually improve results when done strategically through coordinated full and sparse attention mechanisms.
 Usman Salis
Usman Salis


