 Peter Smith
Peter Smith

Artificial intelligence has made impressive strides in language processing and coding, but mathematical reasoning remains the ultimate test of true AI capability. Recent benchmark results reveal a dramatic performance gap among leading models, with Google's Gemini Deep Think establishing itself as the clear frontrunner.
IMO-ProofBench: A New Standard for Measuring AI Reasoning
According to AI researcher Thang Luong, IMO-ProofBench contains 60 proof-based tasks split into two levels: a Basic Set covering pre-IMO to IMO-Medium difficulty, and an Advanced Set featuring high-complexity problems reaching IMO-Hard level.
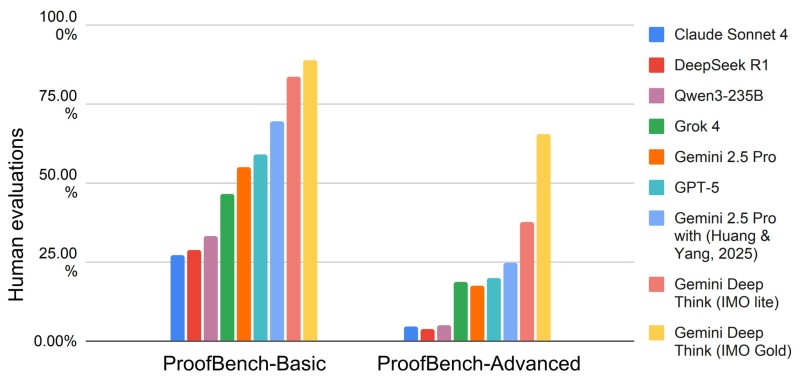
This benchmark evaluates whether models can produce valid, logically consistent mathematical arguments.
Chart Analysis: Gemini Deep Think Dominates the Field
On the Basic Set, Gemini Deep Think IMO Gold achieved approximately 89%, while the IMO Lite version scored 82%. Other models lagged considerably: Gemini 2.5 Pro reached 70%, GPT-5 managed 57%, Grok 4 scored 45%, Qwen3-235B got 29%, DeepSeek R1 achieved 27%, and Claude Sonnet 4 reached 25%.
The Advanced Set results are even more striking. Gemini Deep Think IMO Gold scored approximately 65.7%, while the IMO Lite version managed 35%. All other models fell below 25%, demonstrating that no non-Gemini model can currently handle true IMO-level proof challenges.
Why This Matters: Proof-Level Reasoning Is the New Frontier
Mathematical proofs require capabilities far beyond pattern matching: multi-step logical chains, symbolic abstraction, error-free argument structure, generalization to unfamiliar problems, and verifiability of each inference. These skills are foundational for AI systems designed for scientific research and automated theorem proving. Gemini Deep Think's performance represents a meaningful step toward more trustworthy and analytically capable AI.
 Peter Smith
Peter Smith


