 Eseandre Mordi
Eseandre Mordi

⬤ The latest AI benchmark comparisons put Gemini 3 Flash, Gemini 3 Pro, and GPT-5.2 in a tight race at the top across multiple evaluations. Performance gaps between these leading models keep shrinking, with scores on tests like SWE-bench Verified, HLE, MMLU, GPQA Diamond, AIME 2025, ToolAthlon, and ARC-AGI-2 clustering near upper limits. Many benchmarks are now hitting ceilings that suggest there's not much room left to climb.
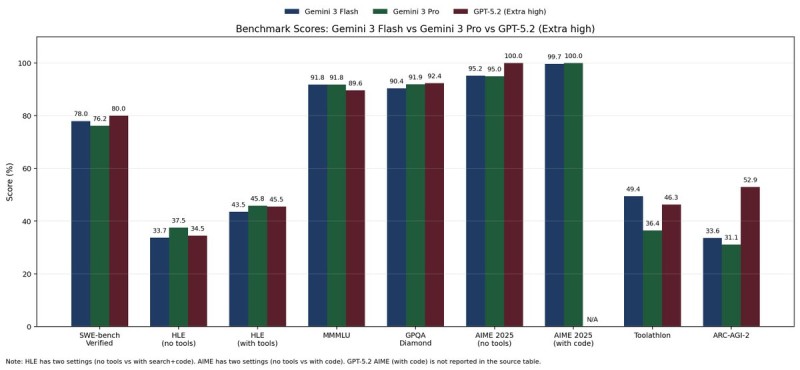
⬤ Software engineering and reasoning tests show especially strong numbers across the board. SWE-bench Verified scores sit in the mid-70s to around 80%, while MMLU and GPQA Diamond push Gemini 3 Flash, Gemini 3 Pro, and GPT-5.2 close to or past 90%. On AIME 2025 without tools, the Gemini models hit the mid-90s and GPT-5.2 reaches a perfect 100%. These results leave little headroom on traditional academic benchmarks.
⬤ Tool use and general intelligence tests reveal more meaningful differences. ToolAthlon places Gemini 3 Flash in the lead near 49%, with GPT-5.2 in the mid-40s and Gemini 3 Pro trailing behind. ARC-AGI-2 shows a clearer spread—GPT-5.2 breaks 50% while Gemini variants land in the low-30s. Some categories like AIME 2025 with code show incomplete coverage, pointing to gaps in testing standards rather than actual performance issues.

⬤ This benchmark convergence matters because it signals a shift in how AI companies will compete going forward. With established leaderboards maxing out, future wins will likely come from specialization, multimodal capabilities, and real-world performance rather than chasing incremental point gains. New evaluation methods that better capture practical use cases are probably on the way, and how leading models adapt to this changing landscape could reshape the AI sector through 2026.
 Eseandre Mordi
Eseandre Mordi


