 Alex Dudov
Alex Dudov

⬤ The AA-Omniscience benchmark from Artificial Analysis just dropped fresh rankings for AI models tackling software engineering work. This isn't your typical speed test—it measures knowledge accuracy and hallucination rates, rewarding models for getting things right while punishing them for making stuff up. The expanded programming language set now covers Python, JavaScript, Go, R, Swift, and more, giving developers a clear picture of which AI actually delivers across different coding environments.
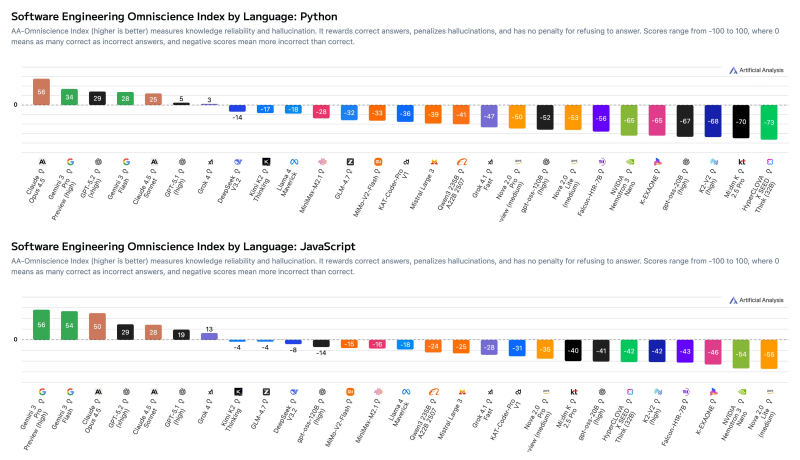
⬤ Claude Opus 4.5 crushes Python with a score of 56, leaving Gemini 3 Pro Preview at 34 and GPT-5.2 at 29 in the dust. But flip over to JavaScript and the tables turn—Gemini 3 Pro Preview hits 56, edging out Gemini 3 Flash Preview at 54 and Claude Opus 4.5 at 50.
⬤ Go is Claude Opus 4.5 territory with a commanding 54, while GPT-5.2 trails at 30 and Gemini 3 Pro Preview lands at 24. For R programming, Claude 4.5 Sonnet takes the crown with 38, followed by Claude Opus 4.5 at 36 and Gemini 3 Flash Preview at 28. Swift belongs to Gemini 3 Pro Preview with 56, then Gemini 3 Flash Preview at 52, and GPT-5.2 at 44.

⬤ The big takeaway? There's no one-size-fits-all champion. Each model has its sweet spot, which means developers need to pick their AI based on what language they're actually working in. This benchmark gives you the roadmap to match the right tool to your specific coding task instead of betting on hype.
 Alex Dudov
Alex Dudov


