 Eseandre Mordi
Eseandre Mordi

⬤ Epoch AI rolled out fresh benchmark data using its Epoch Capabilities Index (ECI), which basically combines a bunch of different test scores into one number. The team then used that score to predict METR's time horizon — essentially how many hours a model can keep working on complicated tasks without falling apart. Gemini 3 Pro came out on top, beating both GPT-5.2 and Claude Opus 4.5 when it comes to staying reliable over longer stretches.
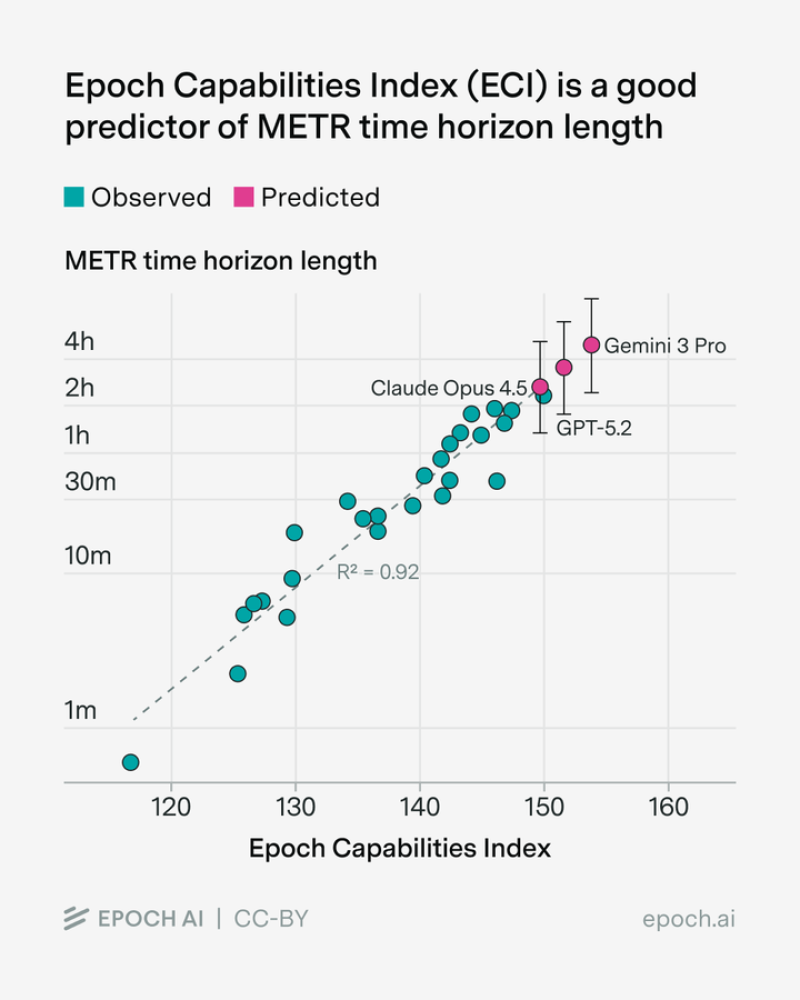
⬤ The predictions paint a clear picture: Gemini 3 Pro clocks in at around 4.9 hours of solid task execution, while GPT-5.2 manages about 3.5 hours and Claude Opus 4.5 hits roughly 2.6 hours. What's interesting is that the ECI score lines up really well with the actual METR results — we're talking an R² of 0.92, which means the prediction model is pretty damn accurate. Gemini 3 Pro sits at the high end of the capability curve, with the other two trailing behind in the exact order you'd expect from both the predicted and observed data points.
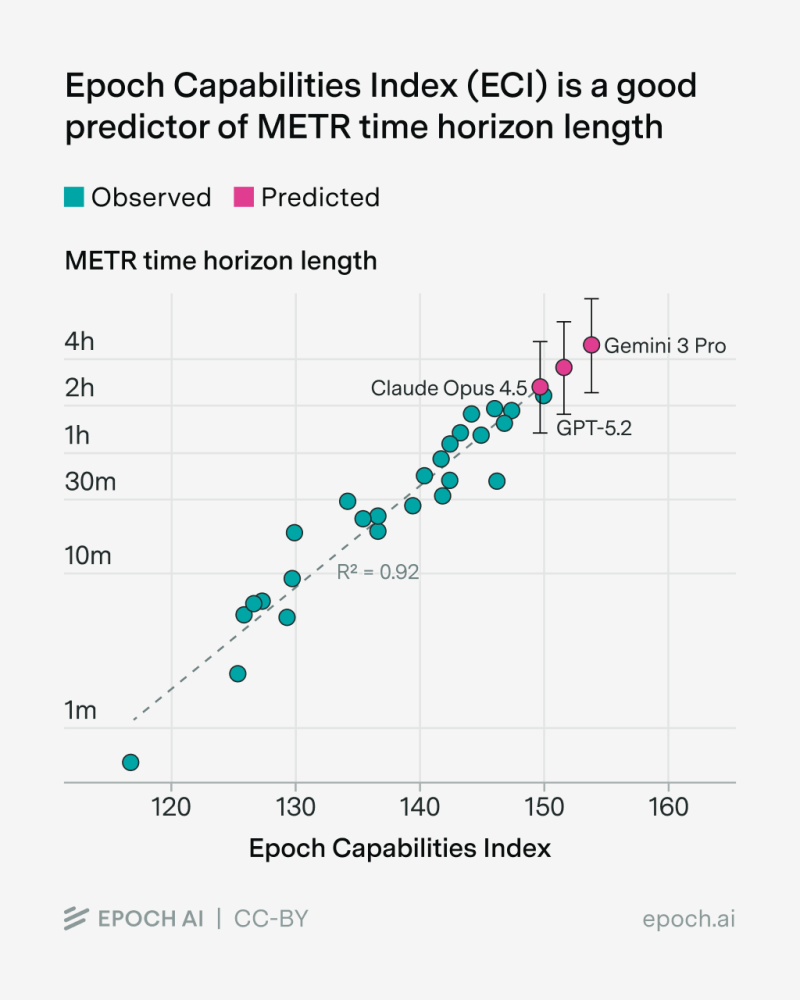
⬤ The chart shows both predicted (pink dots) and observed (teal dots) performance markers, and even with the uncertainty bars thrown in, Gemini 3 Pro still holds its lead. Epoch AI points out that ECI isn't just one test — it pulls together tons of benchmarks covering reasoning, planning, knowledge, and more. That makes it way better at predicting long-duration performance than any single measurement could ever be.

⬤ What this really means is that AI models are getting seriously better at sustained work. Longer time horizons open the door to more complex automation, deeper multi-step workflows, and way more practical use cases for businesses looking to deploy AI at scale. As these systems prove they can handle tasks that stretch across multiple hours, the whole competitive landscape is shifting fast.
 Eseandre Mordi
Eseandre Mordi


