 Peter Smith
Peter Smith

● Robert Youssef recently highlighted Meta's breakthrough research on SPICE (Self-Play In Corpus Environments)—a framework that could change how AI learns. Instead of needing human-labeled data, SPICE lets language models train themselves using real-world text as their learning playground.
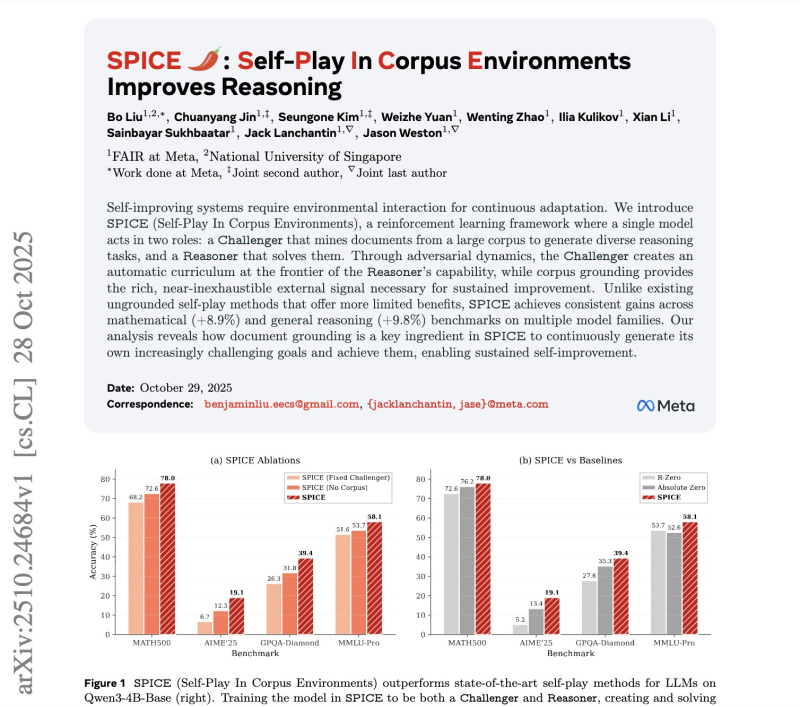
● SPICE uses two AI agents working together: a Challenger that digs through documents to create tough, fact-based reasoning problems, and a Reasoner that tries solving them without seeing the source. This setup creates a self-adjusting curriculum where difficulty increases as capability grows. The concern? If left unchecked, these self-play loops might amplify biases or drift from factual accuracy.
● The numbers are impressive. SPICE boosted the Qwen3-4B model by 9.1% and OctoThinker-8B by 11.9% on reasoning tests—outperforming methods like R-Zero and Absolute Zero. Meta's paper shows average gains of 8.9% in math reasoning and 9.8% in general reasoning. The key difference: learning from real data instead of artificial tasks produces better, lasting improvements.
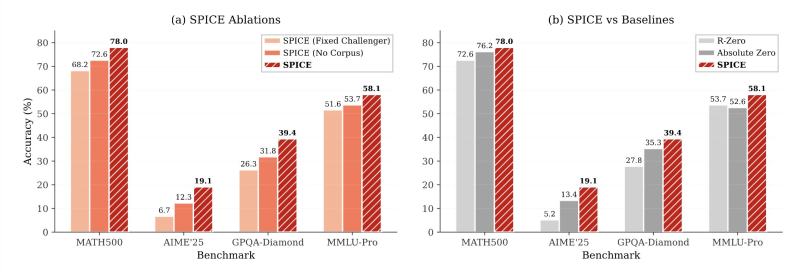
● SPICE marks a shift toward AI that evolves through real-world interaction rather than fixed datasets. By grounding self-play in actual knowledge, Meta built what Robert Youssef calls "a closed-loop system with open-world intelligence."
This flips the script on AI self-improvement. Instead of looping on synthetic junk, SPICE grows by mining real knowledge. As Youssef put it
● If this scales, SPICE could become the template for autonomous AI that doesn't just learn—it continuously teaches itself.
 Peter Smith
Peter Smith


