 Usman Salis
Usman Salis

● Hritik Bansal recently posted early findings on Qwen3-VL-2B-Instruct—a compact multimodal AI model—got significantly better at math and logic reasoning after a single training epoch. The fine-tuned version, called HoneyBee, beat the original across multiple standard benchmarks.
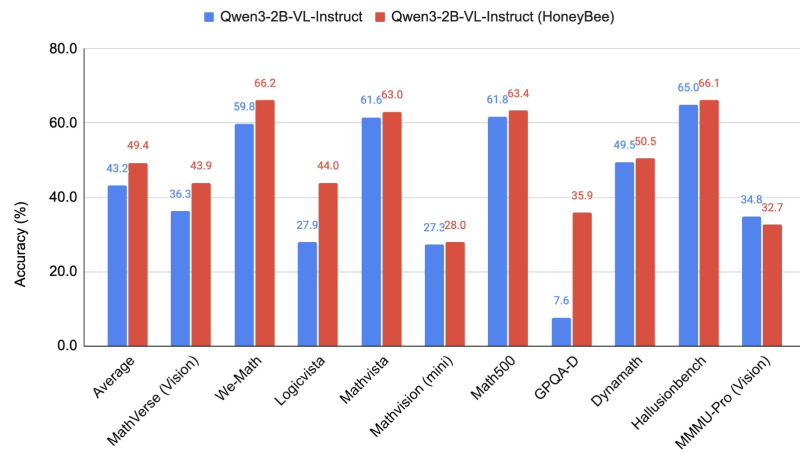
● The team focused on training Qwen3-VL-2B-Instruct using a specialized reasoning dataset. Despite being a smaller model, it showed you don't need massive computational power to achieve meaningful improvements. That said, Bansal noted that quick fine-tuning like this carries overfitting risks—basically, the model might pick up quirks from the training data if you're not careful.
● From a business perspective, these results matter. Better performance from smaller models means lower costs for companies deploying AI in education, analytics, or robotics. The updated model jumped from 43.2% to 49.4% average accuracy, with standout gains on LogicVista (27.9% → 44.0%) and GPQA-D (7.6% → 35.9%), based on Bansal's shared benchmarks.
 Usman Salis
Usman Salis


