 Eseandre Mordi
Eseandre Mordi

Most enterprise AI challenges don't begin with models—they begin with documents. Invoices with irregular layouts, SEC filings packed with tables, scanned pages, and multi-column reports create unpredictable input that breaks traditional text extraction. This week, LlamaIndex and MongoDB showcased a practical solution to handle this complexity at scale.
LlamaIndex and MongoDB Address Real-World Document Complexity
Enterprise documents rarely arrive in clean formats. Traditional text-extraction tools flatten structure, destroy formatting, and lose contextual relationships necessary for accurate reasoning. Jerry Liu from LlamaIndex and MongoDB introduced a production-ready architecture that preserves structure, meaning, and context—tasks where traditional OCR pipelines struggle.
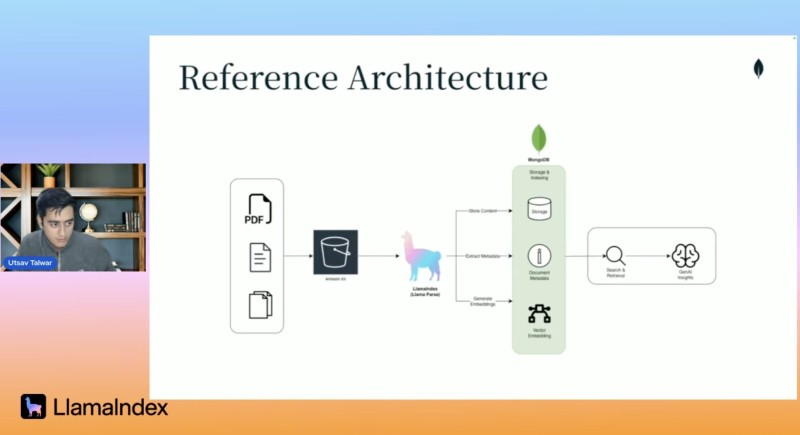
The workflow follows a straightforward path: S3 → LlamaParse → MongoDB Atlas → LLM. Documents of any form—PDFs, scans, reports, invoices, tables—get ingested and stored in Amazon S3, allowing the system to scale across millions of documents.
LlamaParse transforms the pipeline by understanding document structure, reading multi-column layouts, preserving table formatting, extracting images with contextual links, capturing headers and hierarchy, and outputting clean markdown optimized for LLMs. This shift from plain text to structure-aware parsing dramatically improves LLM accuracy.
Parsed markdown and metadata flow into MongoDB Atlas, where information becomes indexable, searchable, and organized. This creates an enterprise knowledge base where every processed document is uniformly structured and easily accessible. Once documents are consistently parsed and stored, LLMs can answer business queries, extract entities, perform compliance checks, summarize reports, and generate insights.
Why This Workflow Matters for Production AI
Real enterprise documents aren't standardized—different vendors and departments use different templates with inconsistent formatting. Traditional extraction breaks structure because OCR tools can't reliably interpret tables, images, or mixed layouts. LLMs need structured input; even advanced models fail when data is unstructured or incorrectly parsed. The LlamaParse–MongoDB workflow solves this by bringing structure back into the pipeline, making large-scale document automation feasible.
 Eseandre Mordi
Eseandre Mordi


