 Eseandre Mordi
Eseandre Mordi

⬤ New MRCRv2 benchmark results reveal GPT-5.2 Thinking crushes its predecessor across input lengths reaching 256k tokens. Industry observers point out that maintaining solid performance over massive context windows has become critical for enterprise AI agents. The upgrade tackles the notorious "context rot" problem where models lose their grip as context expands.
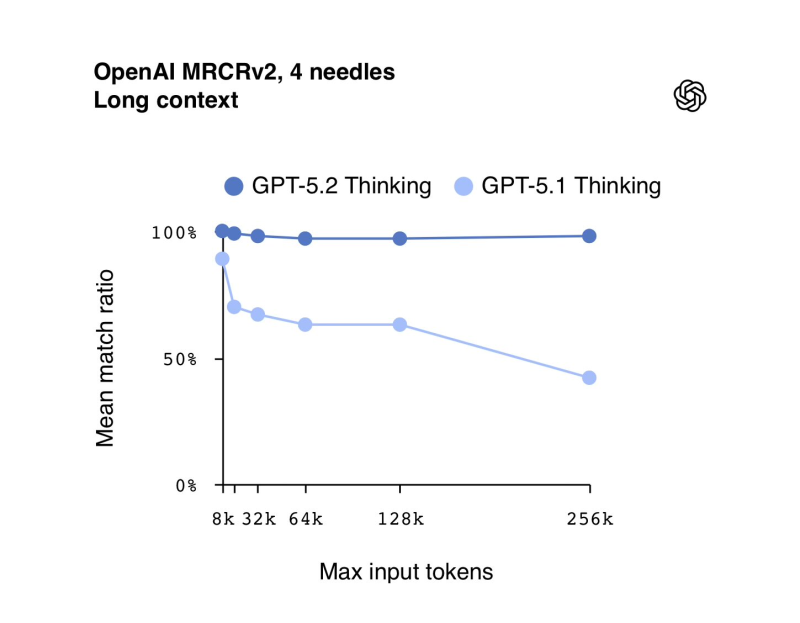
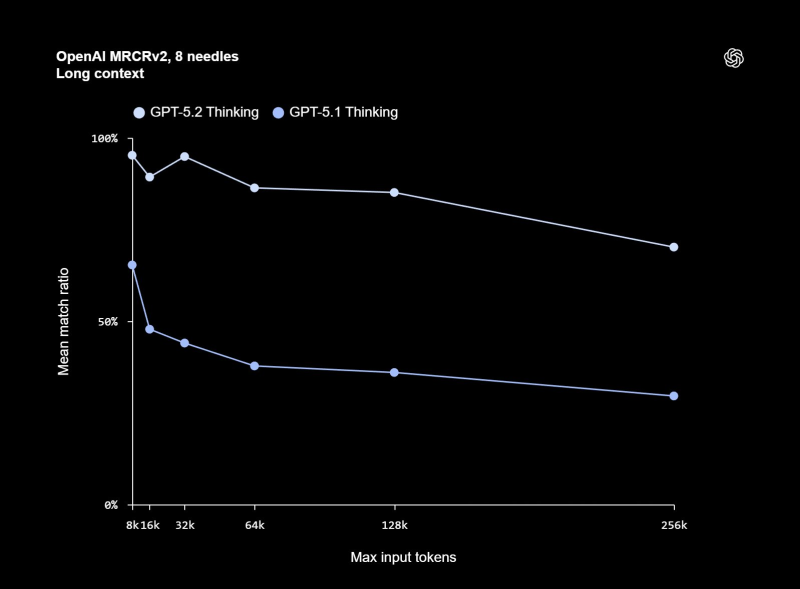
⬤ Benchmark charts show GPT-5.2 Thinking hitting near-perfect scores at shorter windows and keeping high match ratios even when inputs stretch into 128k–256k tokens. GPT-5.1 Thinking, meanwhile, starts slipping noticeably past 64k tokens. The gap widens even more in 8-needle MRCRv2 tests, where GPT-5.2 holds consistent accuracy across all ranges tested.
⬤ Real enterprise work like drafting RFPs, handling complex contracts, writing code, and running extended research projects all benefit directly from reliable long-context reasoning. GPT-5.2's stronger performance lets AI agents follow intricate instruction chains, retain key information across lengthy documents, and execute tasks with fewer mistakes. While memory systems still matter, larger usable context windows dramatically boost what these agents can actually handle.

⬤ These results mark a meaningful shift for enterprise AI development. Companies exploring automated workflows that demand sustained accuracy over long documents now have a model that raises the reliability ceiling. Stronger long-context retention could speed adoption across legal, engineering, finance, and other fields where multi-hour reasoning chains and dense documents are routine. GPT-5.2 positions itself as a potentially game-changing model for the next wave of enterprise AI deployment.
 Eseandre Mordi
Eseandre Mordi


