 Eseandre Mordi
Eseandre Mordi

⬤ Google just dropped a significant upgrade to its AI toolkit with Agentic Vision in Gemini 3 Flash. The feature transforms how the model processes images—moving from single-pass interpretation to an active, multi-step reasoning approach. Rather than generating answers from one quick look, Gemini 3 Flash now works through images methodically using a Think, Act, Observe loop.
⬤ Here's how it works: Agentic Vision lets Gemini 3 Flash write and run Python code while analyzing visuals. The model can zoom in, crop sections, rotate angles, add annotations, count objects, and crunch numbers directly on images. After each adjustment, it re-examines the updated visual data before landing on a final answer. This approach grounds responses in actual evidence, cutting down on hallucinations in tricky visual tasks.
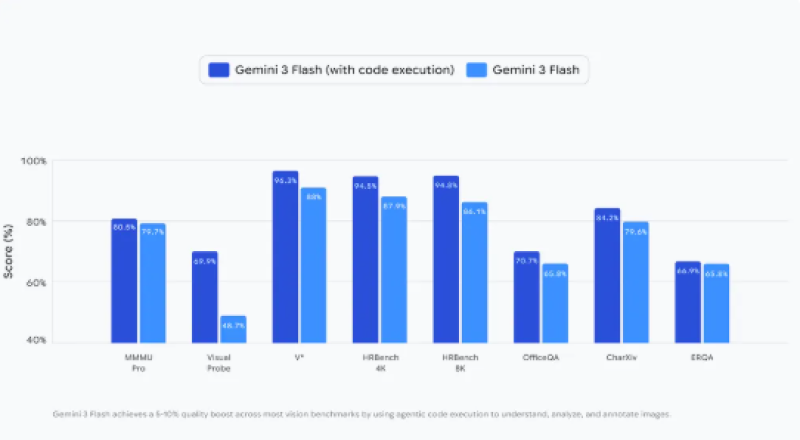
⬤ The numbers back up the upgrade. Benchmark testing shows Gemini 3 Flash with code execution consistently beats the standard version across vision tasks—from multimodal reasoning and image-based Q&A to document analysis and visual problem-solving. Google reports 5-10% quality improvements across most benchmarks when Agentic Vision kicks in, with the biggest jumps showing up in tasks requiring detailed inspection, accurate counting, and complex reasoning chains.

⬤ You can access Agentic Vision through the Gemini API in AI Studio and Vertex AI right now, with a gradual rollout happening in the Gemini app under the "Thinking" feature. This launch fits into Google's bigger push to bake tool use and code execution directly into model reasoning. By blending visual analysis with executable code, Gemini 3 Flash expands what it can handle—visual math, precise annotations, structured image breakdowns—reflecting the industry's shift toward more capable and verifiable AI systems.
 Eseandre Mordi
Eseandre Mordi


