 Eseandre Mordi
Eseandre Mordi

DeepSeek has launched DeepSeek-OCR, a vision-powered model designed to process lengthy documents more efficiently. The innovation centers around Context Optical Compression, which transforms 2D page layouts into compressed vision tokens, dramatically cutting token usage while keeping accuracy intact.
What Makes DeepSeek-OCR Different
Trader Sumanth highlighted the release in a recent tweet, drawing attention to its breakthrough design. The model combines a vision encoder with a language decoder, allowing it to read structured documents, forms, tables, and handwriting efficiently.
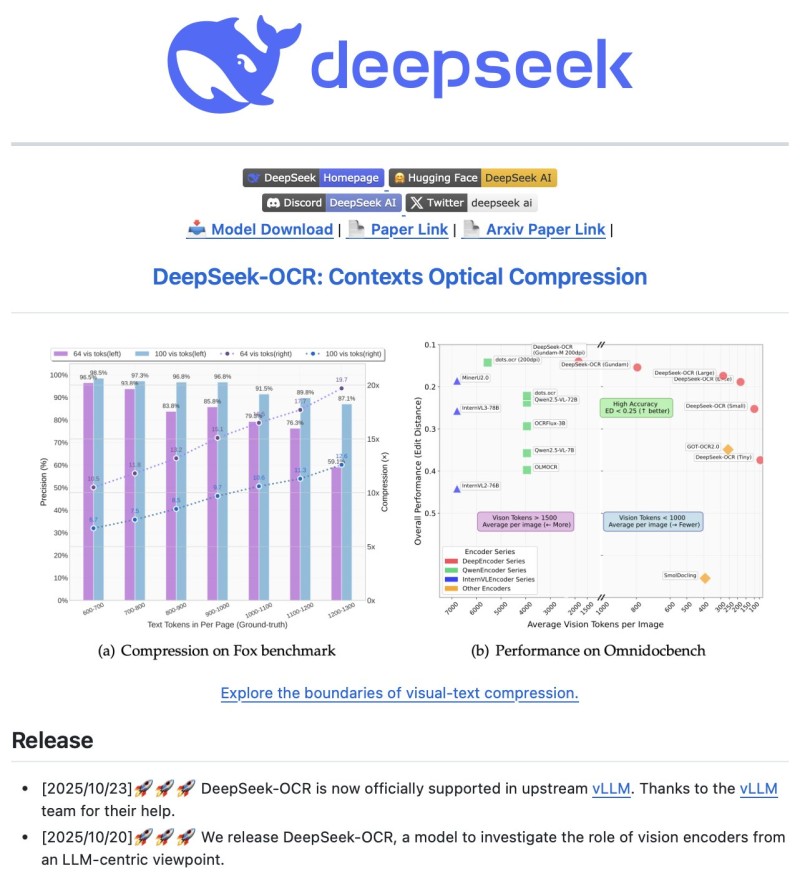
Instead of generating thousands of text tokens from scanned pages, it compresses visual layouts into a fraction of that size.
The official release includes two milestones:
- October 23, 2025: DeepSeek-OCR gains official support in upstream vLLM
- October 20, 2025: DeepSeek formally releases the model to explore vision encoders from an LLM-focused perspective
Performance Insights from Benchmark Data
On the Fox Benchmark, DeepSeek-OCR achieves up to 10× token compression while maintaining 95–97% precision. The compression doesn't compromise quality—it makes processing more efficient without losing important details.
When tested on Omnidocbench against competing models, DeepSeek-OCR delivers high accuracy with minimal token usage. Both model variants show the same strengths—fewer tokens, better performance, and smarter layout understanding.
Why This Breakthrough Matters
Traditional models burn through context windows quickly when processing PDFs or scanned documents. DeepSeek-OCR addresses this by cutting token usage by up to 10× while preserving document structure. It achieves near-state-of-the-art precision and enables long-document understanding without overwhelming memory. This makes it valuable for industries like law, logistics, finance, insurance, and government operations.
Fine-Tuning for Specialized Needs
Developers can fine-tune the model locally. Unsloth AI released a free guide and notebook to help adapt DeepSeek-OCR to custom datasets. This enables domain-specific OCR in medical, legal, financial, or scientific fields, improved handwriting recognition, and full customization without cloud dependency. For organizations with strict data privacy requirements, local fine-tuning is a major advantage.
 Eseandre Mordi
Eseandre Mordi


