 Saad Ullah
Saad Ullah

● New benchmark results shared by alphaXiv show the gap between commercial and open-source OCR systems is shrinking fast. On OmniDocBench—a tough evaluation for document layout and structure—DeepSeek OCR hit 84.24%, barely beating OLmOCR-2's 81.56%. The 2.68-point difference is small enough to be statistically insignificant (p ≈ 0.305), proving that enterprise and open-research approaches are now neck-and-neck.
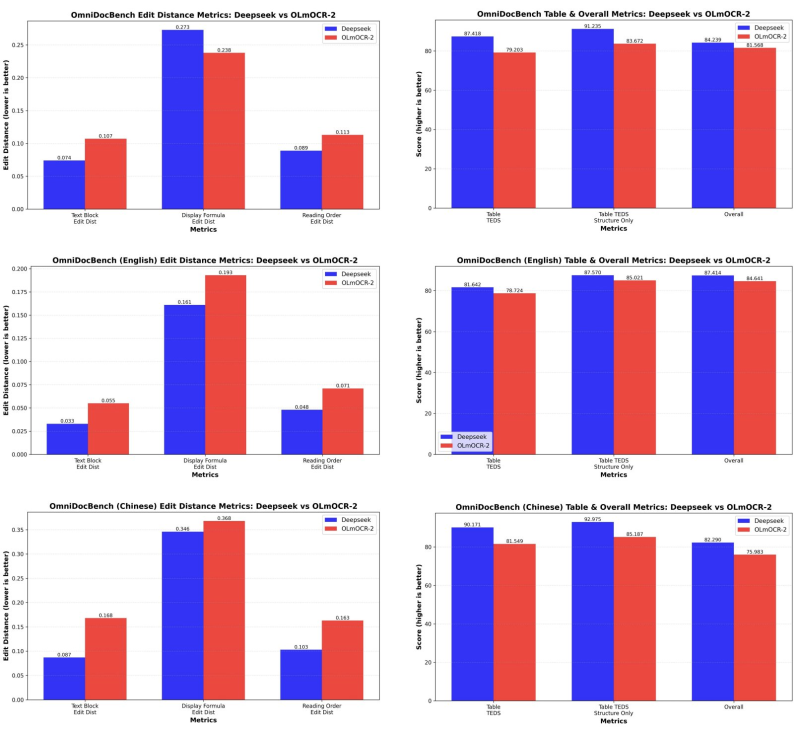
● OmniDocBench tests table accuracy, reading order, and math formula reconstruction. DeepSeek had a slight edge in table structure and overall consistency, while OLmOCR-2 did better with complex equations.
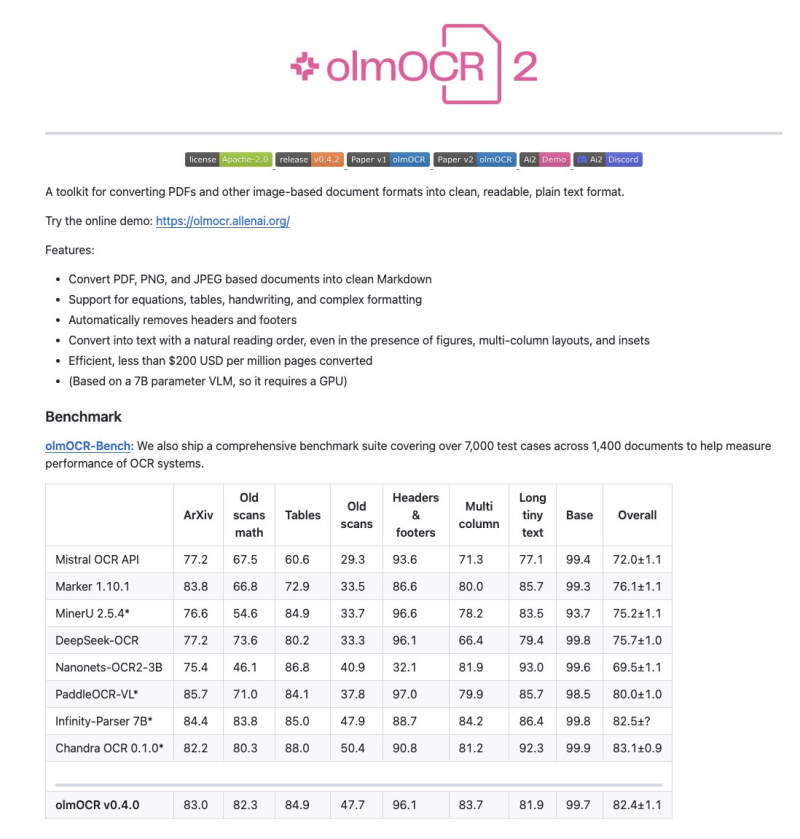
● Shubham Saboo highlighted what makes OLmOCR-2 special: it's fully open-source. Built by the Allen Institute for AI, it converts PDFs and images into clean Markdown while keeping natural reading flow and formatting intact. It handles headers, footers, and multi-column layouts automatically. Despite running on just a 7-billion-parameter model, it costs under $200 per million pages and is available under Apache-2.0 license.
● Official benchmark data backs this up. DeepSeek leads on aggregate scores, but OLmOCR-2 shows solid performance across different datasets, including English and Chinese documents. In multilingual tests, it matched proprietary competitors on tables and long texts.
● Industry watchers see this as proof that open-source AI is catching up. "DeepSeek wins by 2.68%, but it's basically a tie statistically," alphaXiv noted. With public code, datasets, and a demo at olmocr.allenai.org, OLmOCR-2 is becoming the go-to for researchers who want transparent, high-quality alternatives to closed systems.
● The takeaway? Open-source AI is now going toe-to-toe with corporate leaders. As document intelligence becomes critical for business automation, the progress in OLmOCR-2 v0.4.2 and DeepSeek OCR suggests the next breakthroughs might come from collaboration rather than competition.
 Saad Ullah
Saad Ullah


