 Peter Smith
Peter Smith

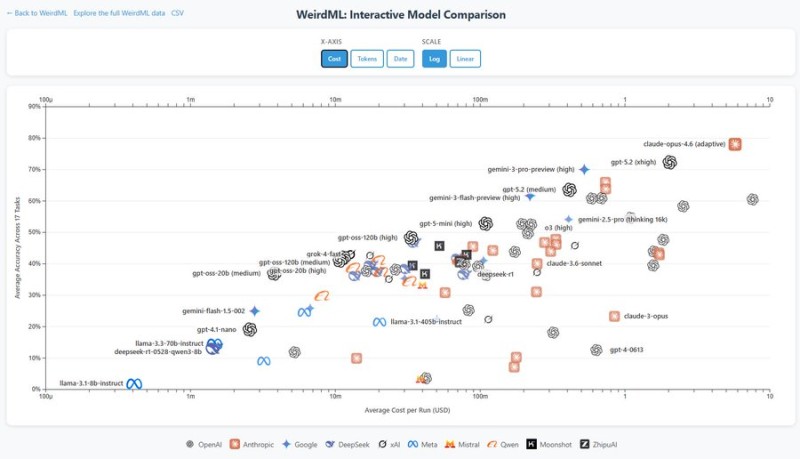
The AI landscape just got more competitive. Fresh benchmark results from WeirdML reveal that Claude Opus 4.6 has pulled ahead of OpenAI's GPT-5.2 in reasoning tasks, though the win highlights a critical industry challenge: balancing performance with efficiency.
Claude Opus 4.6 Outperforms GPT-5.2 by 5.7 Percentage Points
The latest WeirdML benchmark shows Claude Opus 4.6 (adaptive) hitting 77.9% average accuracy compared to GPT-5.2 (xhigh) at 72.2%. The model dominated across three different task categories and achieved an impressive 73% on the notoriously difficult "digits_generalize" challenge—a significant jump from the previous 59% baseline.
These results build on earlier wins documented in Claude Opus 4.6 Crushes Long-Context Tests With 91.9% Score, reinforcing Anthropic's position in advanced reasoning capabilities.
The Hidden Cost: 32,000 Tokens Per Request
But here's the catch. Claude Opus 4.6's performance comes with massive computational overhead. The model averaged roughly 32,000 output tokens per request when adaptive reasoning was enabled—an eye-watering number that raises serious questions about real-world scalability.

"The growing trade-off between reasoning depth and compute efficiency is becoming impossible to ignore," noted the benchmark report.
In several instances, the model couldn't even complete tasks within the 128k token limit. Tasks like blunders_easy, blunders_hard, splash_hard, kolmo_shuffle, and xor_hard had to be run with medium-effort reasoning instead.
Why AI Benchmark Results Matter for Production Deployment
The computational demands also affected testing reliability. Instead of the standard five runs per task, researchers could only manage two, resulting in wider error margins across the results.
This creates a dilemma for companies looking to deploy advanced AI models. Yes, Claude Opus 4.6 delivers superior accuracy, but the cost-per-query could make it prohibitively expensive for high-volume applications.
The Future of AI: Intelligence vs. Efficiency
The WeirdML results highlight a fundamental shift happening in AI development. Raw capability is no longer enough—optimization strategies are becoming just as critical as breakthrough performance.
As reasoning models get smarter, they're also getting hungrier for computational resources. Benchmarks like WeirdML aren't just measuring accuracy anymore; they're revealing which models can actually scale in production environments where cost and speed matter as much as intelligence.
For now, Claude Opus 4.6 holds the accuracy crown. Whether it can maintain that lead while improving efficiency remains the billion-dollar question.
 Peter Smith
Peter Smith


